
In this post I discuss the pros-and-cons of using database-generated integer vs client-generated Guids, and introduce NewId as a way of mitigating some of the downsides of Guids.
Generating IDs: database-side or client-side?
I recently received a pull request to my StronglyTypedId project which added support for IDs generated using the NewId package. The PR was good, but as I wasn't familiar with the NewId package, I thought I'd take a sniff around.
NewId is designed to solve a specific problem. It's for when you want a unique ID, but you want them to generally be sortable, and semi-predictable. One example is when you create IDs for use as primary keys in databases.
For generating entity primary keys, most people fall back to one of the following approaches:
- Use an
intprimary key, and let the database generate the primary key when you insert a row. - Use a
Guidprimary key, generate the ID in your application, and insert it with the row.
To give a bit of context, and to explore why you might want to use NewId, I'll discuss the pros and cons of each of the above approaches to generating primary keys.
Using database-generated IDs
The first option, letting the database generate the primary key automatically, is a very common approach; I'd even go as far as to say it's the default approach in most cases, especially if you're using an ORM like EF Core. One of the very nice things about this approach, is that your primary keys get lovely, monotonically-increasing (and normally, consecutive) IDs.
Probably the best things about this feature is that it makes working with test data much easier as a developer. IDs often appear in application URLs, and being able to test multiple IDs by changing a path from /my-entity/1 to /my-entity/2 is very convenient.
However, there are a number of downsides to using this approach.
First of all, the fundamental approach of generating an ID only at the point you insert an entity into the database makes some common design patterns impossible. For example, a general approach to idempotency is to generate an ID on the client and send it in the request. This allows for easy de-duping, and ensures you don't insert the same entity twice, as it's easy to detect duplicate insertion requests. That approach generally isn't possible with database-generated IDs.
An additional theoretical problem with database generated IDs is that it makes the INSERT code trickier, as you have to make sure to return the generated ID(s). In reality, ORMs such as EF Core help smooth out the fiddly parts of returning the ID in an INSERT row query, seamlessly assigning the ID to your application entities after the insert is complete. If you're using Dapper though (for example), then you're on your own.
One of the big problems with database generated IDs only shows up when you're running at high scale. When you're inserting thousands of rows per-second, then the "lock" the database has to take around the ID generator can sometimes become a bottleneck. Similarly, if you need to scale out, then there's no way to coordinate the IDs between all your servers.
So in summary, database-generated integer IDs are:
- Nice to work with in URLs
- Limiting, as they require a trip to the database, which precludes some patterns
- Can be tricky to return IDs when inserting in some cases (EF Core etc solves this)
- Can cause contention in high throughput scenarios. May make scaling out impossible.
Using client-generated GUIDs
The approach I normally take with IDs is to use client-generated Guids for primary keys. There are various pros and cons for this approach too!
One advantage is that it's easy! All modern languages have UUID generators available; in .NET it's Guid.NewGuid(). This returns a random 128-bit ID. You can set that on your entities, and you don't have to worry about trying to find out what the IDs were after an INSERT. Whether you're using EF Core or Dapper, Postgres or SqlServer, it's all the same. The data only moves one way, client to database, instead of being biderectional.
If you generate your IDs in your client code, you now have access to various idempotency patterns. For example, imagine you include the "requested" Guid ID in a request but the request fails with a server error. You can just send the same request again, safe in the knowledge that the server will be able to identify this as as "duplicate", so it only needs to re-do the work that errored. That way you can avoid creating duplicate entities.
The randomness of Guids are both their strong points and their weakness. From a developer point of view, /my-entity/be170000-f22d-18db-02db-08da21702e9f is definitely not as easy to work with as /my-entity/1!
From a database point of view, this randomness can cause much bigger problems. The randomness of the IDs can lead to severe index fragmentation, which increases the size of your database, and impacts overall performance. There's also the fact that UUIDs are 128-bit vs a 32-bit integer, so there's the pure size of the additional data as well.
So in summary, client-generated Guid IDs:
- Are easy to generate client side
- Enable additional idempotency patterns
- No need to read values from database when doing an insert
- Not as nice to work with in URLs etc
- Larger than integers (128-bit vs 32-bit)
- Can cause database performance problems due to index fragmentation
The benefits of a sortable UUID
So there are several advantages of Guids, and other than some ergonomics, the big downside is the index fragmentation caused by their complete randomness. So, what if we could reduce their randomness?
That's the goal of NewId (which is based on work done by Twitter on Snowflake, and on a similar approach called Flake). Instead of having completely random Guids, you have a UUID that can be easily sorted(-ish!).
The easiest way to understand what this means is to show what the IDs generated by NewId look like. Consider this simple app:
using MassTransit;
foreach (var i in Enumerable.Range(0, 5))
{
NewId id = NewId.Next();
Console.WriteLine(id);
}
This program just generates 5 IDs in quick succession, and writes them to the console. The result is something that looks like this:
be170000-f32d-18db-de59-08da26f2ad5a
be170000-f32d-18db-1816-08da26f2ad5b
be170000-f32d-18db-8694-08da26f2ad5b
be170000-f32d-18db-4dbd-08da26f2ad5b
be170000-f32d-18db-65b3-08da26f2ad5c
On first glance, it might look like these are all the same, but lets break the first instance into 3 sections:
be170000-f32d-18db—this is apparently constant across all IDs.de59—this changes with every ID.08da26f2ad5a—this sometimes changes, and changes gradually.
NewId uses 3 different sources to construct an ID
- A "worker/process ID". This is constant for a given machine (and can be configured to also include the process ID).
- A "timestamp". This provides the basic ordering of the ID
- A "sequence". An incrementing ID.
By combining all 3 together, you can get an ID that is (roughly) orderable, thanks to the timestamp component. By including the worker ID you can have workers independently generate IDS while avoiding collisions. And the use of the "sequence" means you can generate 216-1 IDs per millisecond, per worker:
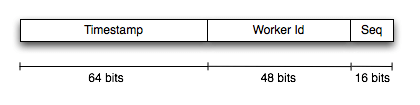
I think the above image shows very well why the IDs can be ordered, but it's fairly obvious that's not quite how NewId arranges them. In the remainder of this post I was going to talk through all the bit fiddling that goes from taking the 3 original sources, and turning them into the final Guid, but frankly, it's not that interesting, and it confused me too much 😂
If you really want to try and decipher it, the code is here, but there's a lot of fiddling that goes on at various points!
Rather than dig through the code I thought I'd jump to the heart of the matter—does it improve index fragmentation!?
Comparing index fragmentation with Guid vs NewId
To test the impact of using NewId compared to Guid, I decided to give it a quick test. NewId appears to be quite focused on MS Sql Server, so to give it a fair try, I decided to test that.
I started by firing up the SQL Server Linux Docker image. Run the following command, and you'll have a local SQL Server up and running in seconds.
This sure beats the mammoth effort that was classically always required to install SQL Server on Windows!
docker run -d --name sql1 --hostname sql1 \
-e "ACCEPT_EULA=Y" \
-e "SA_PASSWORD=Passw0rd!" \
-p 1433:1433 \
mcr.microsoft.com/mssql/server:2019-latest
Once the database was up and running, I connected to it using Rider, and created two simple tables, one for testing Guid IDs, and the other for testing NewId IDs:
CREATE TABLE dbo.normal_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
CREATE TABLE dbo.newid_guids (
Id uniqueidentifier PRIMARY KEY,
Dummy varchar(50) NOT NULL
);
Finally I used Microsoft.Data.Client to generate some test Data. That's right. I went old-school ADO.NET. No, I don't really know why I didn't just use Dapper either.
using System.Data;
using MassTransit;
using Microsoft.Data.SqlClient;
// Connect to the local database using the super-secure password
var connString = @"Server=127.0.0.1,1433;Database=Master;User Id=SA;Password=Passw0rd!;TrustServerCertificate=True";
using var connection = new SqlConnection(connString);
await connection.OpenAsync();
// Insert 10,000 Guids
foreach (var i in Enumerable.Range(0, 10_000))
{
await InsertGuid(connection, "normal_guids", Guid.NewGuid());
}
// Insert 10,000 NewIds
foreach (var i in Enumerable.Range(0, 10_000))
{
await InsertGuid(connection, "newid_guids", NewId.NextGuid());
}
async Task InsertGuid(SqlConnection sqlConnection, string table, Guid id)
{
using var command = new SqlCommand($@"INSERT INTO dbo.{table} (Id, Dummy) VALUES (@ID, 'test')", sqlConnection)
{
Parameters =
{
new("ID", SqlDbType.UniqueIdentifier) { Value = id },
}
};
await command.ExecuteNonQueryAsync();
}
This is all very basic and hacky, because what I'm really interested in is the impact on the index fragmentation. To find that, I used the following query (taken from this link) to show the size of each index and its fragmentation
SELECT OBJECT_NAME(ips.OBJECT_ID)
,avg_fragmentation_in_percent
,avg_page_space_used_in_percent
,page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id)
AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESC
The details of this don't matter, what matters are the results:
| avg_fragmentation_in_percent | avg_page_space_used_in_percent | page_count | |
|---|---|---|---|
| normal_guids | 98.7012987012987 | 75.38790462070669 | 77 |
| newid_guids | 5.084745762711865 | 98.3951321966889 | 59 |
Now this is interesting. The first column, avg_fragmentation_in_percent, shows that the Guids have caused nearly 99% fragmentation in the index, whereas the NewIds have caused only a 5% fragmentation. That shows it's doing exactly what it's supposed to! You can also see that the normal Guids leave more empty space in each page, so consequently you need more pages to hold the same amount of data (77 vs 59). This is the source of some of the performance hit from using Guids.
So NewId is clearly doing what it says on the tin here. But should you use it? As always, that depends on your situation, but it seems like a good option to me, especially if you're working with MS SQL Server, and you're careful about setting the worker ID as necessary.
Summary
In this post I discussed the options for generating IDs for your entities. I described using database-generated integration IDs and client-generated Guids, and the pros and cons of each approach. Next I introduced NewId which produces "sortable" Guids, based on Twitter's Snowflake protocol. Finally, I compared the impact on a MS SQL Server index of using Guids compared to using NewId, and showed that it dramatically reduces the fragmentation.