
In this post I describe a .NET script/tool I created to migrate the comments on my blog posts from my legacy Disqus account to GitHub discussions. In this first post I discuss the process of parsing and cleaning the exported Disqus data. In the next post I discuss interacting with the GitHub GraphQL API.
Moving from Disqus to Giscus
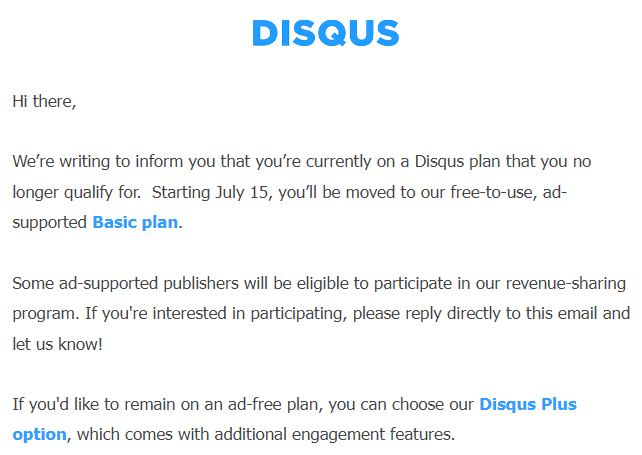
Back in July of 2022, I floated the idea of moving the comments section of my blog from Disqus to the GitHub discussion-based tool, giscus, after receiving an email indicating that Disqus would be charging for an ad-free experience:
Everyone who commented on my post seemed in favour of giscus—bearing in mind that everyone who commented was currently using Disqus. But to be sure, I also did a super-scientific Twitter poll:
Blogged: Considering replacing Disqus with Giscus - I'd love to get people's thoughts on what I should do, now that Disqus is forcing ads for their free tier.
— Andrew Lock "Sock" (@andrewlocknet) July 26, 2022
As explained in the post, Giscus is a GitHub based commenting system:https://t.co/mkzFpPFy4T #dotnet #dotnetcore
0 people suggested sticking with Disqus, so in my next post I described how I added giscus to my blog. It was all pretty straight forward, and I've described it in detail in that post.
I had only one thing remaining: migrating the existing Disqus comments to Giscus. And it's taken me almost a year to get around to that 😬
Prior art
I'm not the first person to make this transition from Disqus to giscus, and I picked up little bits of information and code from lots of different places, so I want to give credit where it's due:
- This blog post by Jürgen Gutsch, started me down the migration road, though he uses utterences (which uses GitHub issues) rather than giscus (which uses GitHub discussions).
- Along with the blog post, Jürgen provides the code he used to migrate to utterences. I was initially planning on using this code almost directly, but I ended up rewriting most of it in the end.
- This post from Yihui Xie described some of the issues they ran into doing the migration, and made me add some niceties to the migration script, which I discus later in this and the next post.
- This big post from Brice Dutheil includes their whole migration journey to giscus including the migration of their Disqus comments. They provide a java script for doing the migration, and again highlight some problems that I describe later in this post.
For the rest of the post I describe the general approach I took, some of the difficulties I ran into, and how I resolved them. I'll describe bits of the .NET script/tool I wrote to do the migration, but you can find the whole thing on GitHub here.
Be aware, I didn't bother generalizing the tool particularly (as I won't need to do this again), so some parts are highly tailored to my blog. It shouldn't be too hard to update it to work with your own blog and data, but it's not a turnkey solution currently.
Migrating Disqus comments to Giscus
The whole process of migrating followed approximately the following steps:
- Export your comments from Disqus
- Parse the Disqus XML into .NET types and convert from Disqus' nomenclature to Giscus nomenclature
- Clean up the data (remove deleted, spam, orphan comments, and comments on other people's blogs)
- Associate Disqus users with GitHub users (where possible)
- Convert comments from Disqus' "deep" threading model to GitHub's "shallow" threading
- Fix Disqus user "
@" references in comments - Fix truncated URLs in comments
- Find associated discussion for each Disqus post
- Create GitHub discussion for each post where discussion doesn't exist
- For each top-level comment and replies, post to GitHub.
When I started, I didn't expect a 10 point plan 😅 Things were a lot more complicated than I expected. And I probably also got caught up with being somewhat of a perfectionist about the results.
On top of the general process above, there were various miscellaneous pain points and issues to handle along the way:
- Dealing with GitHub's rate limit
- Dealing with GitHub's abuse filters
- Creating a "bot" account to post the comments from other users
- "Checkpointing" to ensure idempotency
I'll tackle the last point in this post, but I'll save the other points for the next post in which I discuss interacting with the GitHub API.
1. Exporting your comments from Disqus
The first step is to get your data out of Disqus. Luckily this is pretty easy. Login to Disqus and go to the Export page. From here you can click the "Export Comments" button.

Disqus will shortly send you an email containing a link to download a gzip XML file containing all your comments, called something like andrewlock-2023-04-29T23_21_12.805294-all.xml.gz.
Extracting the gzip file is a bit of a pain on Windows, so I nipped into WSL and used gzip -d <path> to decompress the XML file:
gzip -d andrewlock-2023-04-29T23_21_12.805294-all.xml
This replaces the .xml.gz file with a .xml file that we can now extract the comments from.
2. Parsing the Disqus XML
The next step was to parse the XML document into .NET objects we can use. For this I stole a lot of the work Jürgen did in his script. It mostly involves messing with XmlDocument to extract the values we want from Disqus' (in my opinion) slightly funky schema. A couple of points of note here:
- A Disqus
<thread>is what I would think of as a "blog post". Note that this isn't just posts on your blog, it may include posts on other people's blogs, as well as (in my case) non-existent testing URLs likelocalhost. It includes elements/attributes for- The blog post title
- The URL
- An internal ID
- A Disqus
<post>is what I would think of as a "comment". It includes details about:- The author (Disqus username + display name)
- The comment body as HTML
- Date created
- Was the comment deleted?
- Was the comment marked as spam?
- Parent comment (if any)
- Associated blog post
3. Cleaning up the XML data
During the XML parsing process I automatically excluded any comments marked as spam, as well as any deleted comments (deleted comments contain no other data anyway). Unfortunately, this caused issues later when I realised there were some comments that shouldn't have been marked as spam, as well as replies to deleted comments, which caused some orphan comments.
Rather than edit the XML itself I hard coded a list of comments that should always be included (because they were incorrectly marked as spam) or always excluded (because they were replies to orphaned comments). This is where embracing the "hacked together" nature of the project really came through, don't judge me 😅
As well as filtering the comments, I also excluded any posts that were from other people's blogs or were from "test" pages. To do this, I read all the "source" markdown files that make up the posts on my blog, inferred the URLs, and excluded anything that didn't match.
Loading the files from disk was a lost quicker than using the approach Jürgen took of making HTTP requests to the URLs to verify authenticity. It also meant I could read the YAML metadata for the posts, which I needed later when creating the discussions on GitHub.
4. Associate Disqus users with GitHub users
One of the slightly disappointing things about migrating is that users who had written lots of comments on my blog would no longer have all those discussions tied back to them. I came up with the idea of creating links between users's Disqus accounts and their giscus accounts, so I could @ them in the GitHub discussion comments:

The difficulty was mapping from abstract Disqus handles to GitHub handles. I took a brute-force attempt of manually scrolling through the list of 1,775 distinct authors for names I recognized and making a note of them. The whole process was highly inefficient, biased, and not very effective—I only pulled out about 40 names that I was confident of being able to reliably grab the GitHub handles for.
One thing I didn't think about was that using someone's handle in a discussion, referencing a comment they made potentially years ago, flooding their email with notifications, was a bit anti-social 😬 So apologies if you were one of the "lucky" 40!
5. Convert from Disqus' threading model
The threading model on Disqus is one in which you can have infinitely deep threads, with replies to replies to replies:
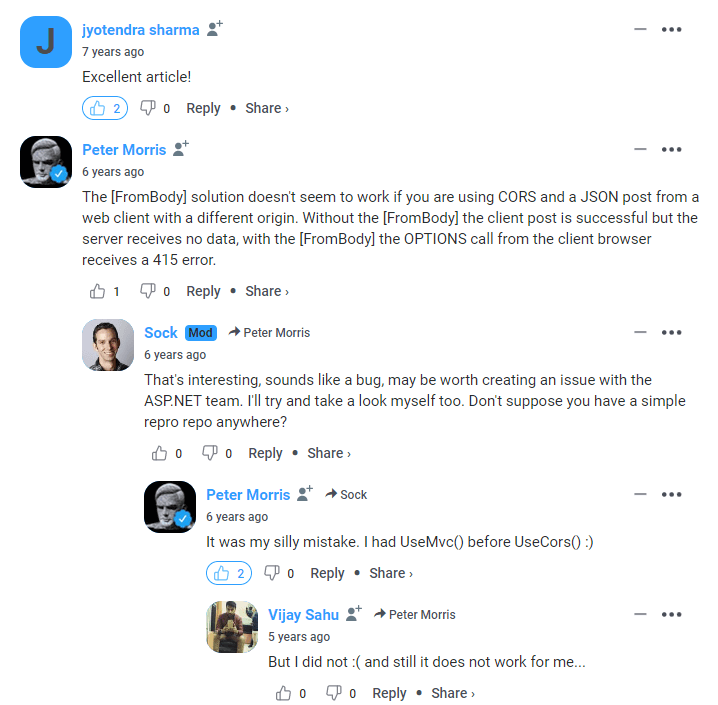
In contrast, on GitHub discussions, you can have "top-level" comments (on a white background), with replies to these (on a grey background), but the replies are all "flat". You can't reply to a reply.
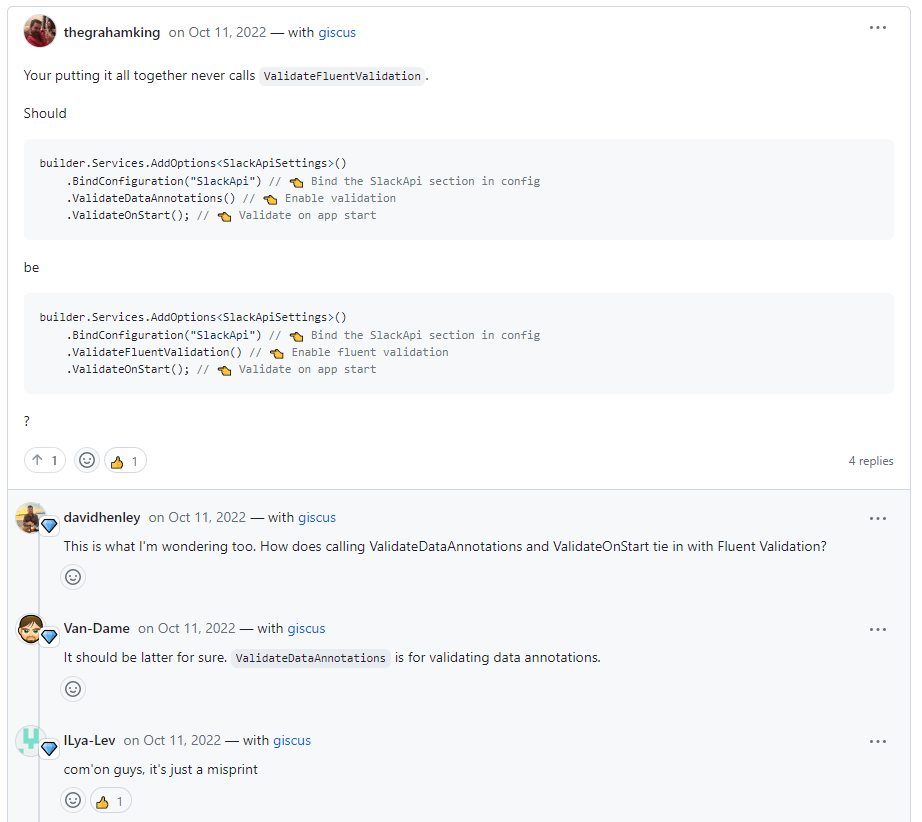
To work around this mismatch, I "reparented" each of the child comments to be a reply to the "top-level" comment, and sorted the replies by creation date. Generally speaking, complex comment hierarchies were rare, so this wasn't a bit problem. I kept a reference to the original parent comment though, so that I could make it clear which was the original parent when posting the comment on GitHub.
6. Replacing Disqus @ with GitHub @
Disqus comments allow you to reference other Disqus users directly using the familiar @username syntax. In the HTML of the Disqus comments, it looks something like this:
<p>Hi @some_name:disqus, thanks for the kind words</p>
As you can see in the HTML above, the @username display is given a :disqus suffix. This made it nice and easy to do a Regex replacement so that we can replace it with the "display name" instead of the "some_name"
private static readonly Regex DisqusUserRegex = new(@"@([\w_\-0-9]+)\:disqus");
private static readonly Dictionary<string, Author> Authors;
if (DisqusUserRegex.Match(comment.Message) is {Success: true, Groups: {Count: 2} groups})
{
var username = groups[1].Value;
var author = Authors.TryGetValue(username, out var known)
? known.AuthorAnchor
: username; // may be a deleted user we don't know about
comment.Message = DisqusUserRegex.Replace(comment.Message, author);
}
After the change, the message looks something like this:
<p>Hi <a href="https://disqus.com/by/some_name/">Joe Bloggs</a> thanks for the kind words</p>
7. Fix truncated URLs in comments
Another "feature" of the Disqus HTML is that links are often "truncated", so they look like this https://github.com/dotnet/c... instead of showing the full URL. The HTML looks like this:
<a href="https://github.com/dotnet/corefx/blob/master/Documentation/architecture/net-core-applications.md" rel="nofollow noopener" title="https://github.com/dotnet/corefx/blob/master/Documentation/architecture/net-core-applications.md">https://github.com/dotnet/c...</a>
I'm not a fan of this, so I wanted to replace these with the full URL. For this I pulled in AngleSharp and did a quick bit of hacky "find and replace":
using AngleSharp.Html.Parser;
var htmlParser = new HtmlParser();
var message = htmlParser.ParseDocument($"<html><body>{comment.Message}</body></html>");
foreach (var anchor in message.QuerySelectorAll("a").Where(x => x.InnerHtml.Length > 3))
{
var href = anchor.Attributes["href"]?.Value;
var innerHtml = anchor.InnerHtml;
var subIndexHtml = innerHtml.Substring(0, innerHtml.Length - 3);
if (href is not null && href.StartsWith(subIndexHtml))
{
anchor.InnerHtml = href;
}
}
comment.Message = message.Body.InnerHtml;
And with that, we've finally finished massaging the Disqus XML into something we want!
8. Finding an associated discussion for each Disqus post
The first step in uploading comments is to make sure there's a corresponding GitHub discussion. I use giscus' strict matching based on the blog post URL's path, which means the discussion includes the SHA1 hash of the page's path. You can use this hash to reliably search for a matching discussion on GitHub.
This post is already too long, so I will describe how I worked with the GitHub API using the Octokit.GraphQL.NET library in the next post.
To calculate the SHA1 hash of a blog-post URL in the same format that giscus uses, I used the following:
// Strip the leading `/` off the path
// e.g. for https://andrewlock.net/some-path/
// this gives some-path/
var title = new Uri(Url).AbsolutePath.Substring(1);
byte[] bytes = Encoding.ASCII.GetBytes(GitHubDiscussionTitle);
byte[] hash = SHA1.HashData(bytes);
// This now contains the correct search term
var searchTerm = Convert.ToHexString(hash).ToLowerInvariant();
To avoid over-loading the GitHub API (more on that in the next post), I decided to pull down all the discussions created in my repo, and search for a discussion in memory, instead of using GitHub's search API.
9. Create missing GitHub discussions
If searching reveals that a discussion for the post doesn't exist, we need to create it. That's generally pretty easy, I just tried to match the same format for the discussion body that giscus uses for the post, for example:
# an-introduction-to-session-storage-in-asp-net-core/
Web applications often need to store temporary state data. In this article I discuss the use of Session state for storing data related to a particular user.
https://andrewlock.net/an-introduction-to-session-storage-in-asp-net-core/
<!-- sha1: b46349976449f650e5d52e32f547657697342298 -->
Ideally giscus would use the post's title instead of it's path in the discussion body (as well as for the discussion's title), while still using the URL path to calculate the sha1 hash (as that's more likely to be unique and stable). Unfortunately that doesn't seem to be possible yet, which means I'm stuck with the slightly ugly discussion titles.
To create the discussion I used the Ocotokit.GraphQL.NET library as I'll discuss in the next post. Creating the discussion entry is another place where I needed the YAML frontmatter for my posts so I could include the excerpt/description of the post in the discussion body.
10. Create comments
Once the discussions were all created and associated with my the in-memory Disqus comments, all that was left to add the comments and replies.
Unfortunately, that was a lot harder than I anticipated, but I'll go into that more in the next post!
Checkpointing
A final point I want to touch on is the "restartability" of the script. I quickly realised that I was going to need to run this script multiple times as I ran into corner cases, rate limits, and errors.
To avoid creating duplicate comments or discussions I decided to create a "checkpointer" that would dump the entire state of the app after each comment was added. When I comment was added, I'd record its ID alongside the Disqus comment. The whole object graph was then serialized to a JSON file.
If I hit a rate limit or an error, the app would exit. When re-running, I'd pass in the path to the "state" file, and it would reload, skip over any discussions/comments that had already been created, and continue from where it left off.
This system was certainly crude, but it worked perfectly for me. The serialized data was 3MB, but it had negligible impact on the script as a whole because GitHub was invariably the limiting factor. And it meant I didn't need to worry about hitting the rate limit.
And be warned, I hit the rate limit a lot. More on that in the next post.
Summary
In this post I provided an overview of how I ported my Disqus comments to GitHub using a simple tool/script I wrote in .NET. I describe the basic process I took to download and clean the XML data that came from Disqus, and how I converted it to a format compatible with GitHub discussions. In the next post I describe how I used Octokit.GraphQL.NET to call the GitHub discussions API.