In this post I describe some scenarios in which you need to change git branches frequently and why this can sometimes be annoying. I then present some possible ways to avoid having to change branch. Finally I describe how git worktree allows you to check out multiple branches at once, so you can work on two branches simultaneously, without impacting each other.
Scenarios requiring frequent branch changes
Have you ever found yourself having to swap back and forth between different git branches, to work on two different features? Git makes this relatively easy to do, but it can still be a bit annoying and time consuming. There are various scenarios I have encountered that require me to switch from one branch to another.
Scenario 1: helping a colleague
The first scenario is when you're working on a feature, coding away on your my-feature branch, when a colleague sends you a message asking to give them a hand with something on their branch other-feature. You offer to checkout their branch to take a look, but that requires a number of steps:
- Save the code you're working on. You could use
git stash --allto save the changes and any new files for all. Or you could create a "dummy" commit on your branch usinggit commit -m a "WIP"(which is my preference). - Switch to the other branch. You could use the UI in your IDE (e.g. Visual Studio, Rider), or you could use the command line
git checkout other-feature, orgit switch other-feature. - Wait for your IDE to catch up. I find this is often the most painful step, whether I'm using Visual Studio or Rider. For big solutions, it can take a while for the IDE to notice all the changes, reparse the files, and do whatever it needs to do.
- Make changes. From here you can work as normal, commit any changes and push them to the
other-feature. Once you're done, it's time to switch back,goto 1.
This is a conceptually simple set of steps to follow, with the most painful step in my experience being 3—waiting for the IDE to finish doing what it needs to before you can be productive again—and the scenario probably happens rare enough that you don't worry about it too much.
Anecdotally, I've found IDEs get much less "confused" if you use their built-in support for switching
gitbranches, instead of changing them from the command line and waiting for the IDE to "notice" the changes.
Scenario 2: fixing a bug
In this scenario, you've just finished a feature and pushed it out. Unfortunately, it has a bug, and you need to fix it quickly. Unfortunately, as you've already started working on my-feature, this involves the exact same steps as in the previous scenario.
Scenario 3: working on two features at once
This last scenario, working on two separate features at once, sounds like a bad idea. Aside from the technical issues we're describing in this post, there's a productivity cost to constant context-switching. Unfortunately, it's a scenario I find myself in relatively regularly.
In my day-job I often work on the CI build process. We're constantly trying to optimise and improve our builds, and while we use Nuke to ensure consistency between our local and CI builds, some things have to be tested in CI.
As anyone who has worked with CI will know, working on a CI branch leads to commits that look like this:

Each of those commits fixes a tiny change, which then needs to be pushed to the server, and wait for a CI build to complete. Depending on your CI process, this could lead to a long cycle time, where you have to wait for an hour (for example) to see the results of your changes.
Due to this cycle time, I normally work on something else in the mean time while I wait to see the fruits of my CI labour. Which means going through the same steps as in scenario 1 above every hour or so. When the results of the CI change are back, I stash my work-in-progress, switch to the ci-feature branch, make my changes, trigger another build, and switch back to the my-feature branch.
Adding in the IDE branch-switching tax, that gets frustrating quickly. To avoid this, I looked around for ways to make it easier to work on two branches at once
Working on multiple git branches at once
Just to be clear, switching branches with git alone is quick and easy. The friction comes in when you're working in a large solution, as this makes branch changes more expensive for IDEs (as they have to do more work to look for changes and update their internal representations etc). That friction led me to consider ways to avoid having to switch branches.
Solution 1: Work in the GitHub UI
The easiest solution to avoiding the issues with changing branches locally is: don't change branches locally. That seems a strange suggestion, but often, especially when I'm working on CI, editing a branch directly using the GitHub CI is sufficient. This is especially true using the new github.dev experience built-in to GitHub.
To activate github.dev for a repository press the . key from the github.com repository.
https://github.dev gives you a browser-based VS Code editing experience which is far superior to the experience you get on https://github.com. From here you can create and switch branches, edit multiple files, and commit them. This is often more than enough for making a quick-edit or fixing a typo.
Where this falls down is with more complex tasks when you need that full IDE experience.
Solution 2: Clone the repository again
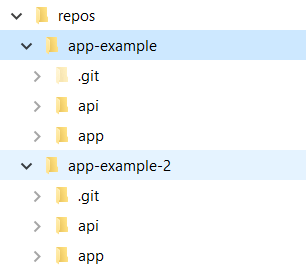
The brute-force way to work on two git branches at once is to clone the entire repository to a different folder, and check out a different branch in each clone. In the example below, the same repository is cloned in app-example and app-example-2:
This certainly gets the job done. You can open the solution in each clone in a separate instance of the IDE, and never have to switch branches. Your IDE is happy as it doesn't have to keep re-parsing, and you switch branches as easily as switching windows.
Unfortunately, this has some downsides.
- Duplication of data. As you can see in the image above, the two clones have their own .git folders, which contains all the history of the repository. This folder is essentially identical between the two clones
- Duplication of the update process. As the two clones are completely independent, whenever you want to update your local clones by doing a
git fetchorgit pull, you have to repeat the process in the other clone if you want everything to be up to date. - No local sharing of branches. Again, as the two clones are independent, changes you make in a branch in
app-examplewill not be visible in the associated branch inapp-example-2. The only (sane) way to synchronise local branches between the two clones is by pushing the local branch as a remote and pulling it in the other clone. This can add some friction to something that feels like it shouldn't be so hard.
I say the only "sane" way, because you could add the
app-exampleclone as anothergit remotesource to theapp-example-2clone, but in this way madness lies.
Solution 3: git worktree
The last solution I'm aware of is to use git worktree. This is very similar to solution 2 in how you work with it, but it manages to solve all of the problems I listed above. For the remainder of this post I'll describe how to use git worktree, and how it lets you work on two git branches at once.
Multiple working trees with git worktree
git has the concept of the "working tree". These are the actual files you see in the folder when you checkout a branch (excluding the special .git folder). When you checkout a different branch, git updates all the files on disk to match the files in the new branch. You can have many branches in your repository, but only one of these will be "checked out" as the working-tree so that you can work on it and make changes.
git worktree adds the concept of additional working trees. This means you can have two (or more) branches checked-out at once. Each working tree is checked-out in a different folder, very similar to the "multiple clones" solution in the previous section. But in contrast to that solution, the working-trees are all linked to the same clone. We'll explore the implications of that shortly.
Managing working-trees with git worktree
As always with git there are a bunch of different ways to use git worktree, and a variety of switches you can provide. In this section I'll show the basics of using git worktree based on the scenarios I showed at the start of this post.
Creating a working tree from an existing branch
In the first scenario, a colleague asks you to take a look at an existing branch. You're in the middle of a big refactor in your branch, and rather than stash your changes, you decide to create a new worktree to take a look. The branch you need to look at is called other-feature, so you run the following from the root directory of your repository:
$ git worktree add ../app-example-2 other-feature
Preparing worktree (checking out 'other-feature')
HEAD is now at d6a507b Trying to fix
In this case, the git worktree command has three additional arguments:
addindicates want to create a new working tree../app-example-2is the path to the folder where we want to create the working-tree. As we're running from the root-directory, this creates a folder called app-example-2 parallel to the clone folder.other-featureis the name of the branch to check-out in the working tree
After running the command, you can see that git has created the app-example-2 directory, and that it contains the checked out files:
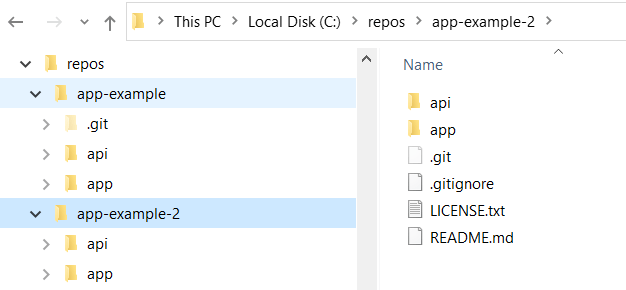
The eagle-eyed among you may notice that there isn't a .git directory in the app-example-2 working tree. Instead, there's a .git file. This file points to the git directory in the original clone, and it means that all your usual git commands work inside the app-example-2 directory, as well as in the original app-example directory.
I'm not going to go into the technical details of how this all works, see the manual for details if you're interested.
After helping out your colleague, you no longer need the other-feature working tree around. To remove it, run the following from your "main" working tree (in the app-example directory):
git worktree remove ../app-example-2
This will delete the app-example-2 directory. The branch it was pointing to is obviously not affected, it just won't be checked out any more.
If you have uncommitted changes in the linked working tree, git will block you from removing it. You can use
--forceto force the removal, if you're sure you want to lose the uncommitted changes.
Creating a working tree from a new branch
In the second scenario, imagine you need to make a quick bug fix. In this case, you don't have a new branch yet. git worktree has a handy -b option to both create a new branch and check it out in the new working tree:
> git worktree add ../app-example-2 origin/main -b bug-fix
Preparing worktree (new branch 'bug-fix')
Branch 'bug-fix' set up to track remote branch 'main' from 'origin'.
HEAD is now at 37ae55f Merge pull request #417 from some-natalie/main
This example creates a new branch, bug-fix from the origin/main branch, and then checks it out at ../app-example-2. It can be removed from the main working tree by running git worktree remove ../app-example-2, as before.
Switching branches inside a working
That brings us to the final scenario, where I have two long running branches I want to have open at once. From the git worktree point of view, this is the same as the previous scenarios. You simply create a new working tree (and optionally a new branch) at the other location. You can work on this from your IDE, and it will treat it just like a "normal" git clone.
In my case, I've tended to create "long-running" working trees. The "main" feature I'm working on goes in my "main" working tree; the side feature/CI feature I'm working on goes in the "linked" working tree. But instead of removing the linked working tree when I'm finished with it, I keep it around. So I have a "permanent" linked tree at app-example-2, that I can use to check out a different branch at any time I need.
It seems like a lot of overhead, but thankfully it's really not, as it solves most of the issues of dealing with multiple clones.
The advantages of git worktree
While it obviously is more confusing to have two working trees than just a single working tree, git worktree solves all the issues associated with having multiple clones.
- Duplication of data. the linked working tree is using the same data (i.e. .git folder) as your main working tree, so there's no duplication
- Duplication of the update process. If you do a fetch in one of your working trees, or if you rename a branch in the other working tree, the changes are immediately visible in all the working trees, as you're operating on the same underlying data.
- No local sharing of branches. Again, as you're using the same data, it's easy to share local-only branches between working trees, so you have none of the issues you do when using multiple clones.
I've only shown some of the most basic usages of git worktree here, but there are many different things you can do if you want (create a working tree without checking out a branch, lock a working tree, add custom configuration etc.). For more details, see the manual.
Disadvantages/gotchas of git worktree
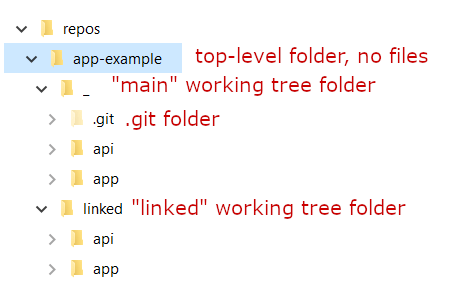
The biggest mark against git worktree is the simple overhead of having two "top-level" folders for a single repository. But this is a big mark against it. If this is a pattern you're going to use consistently, I suggest nesting all your workings tree inside a sub-directory, something like this:

I've suggested using
_as the main working tree folder name so it's generally going to be sorted at the top of the folder list in explorer.
Another thing to be aware of is that you can't checkout the same branch in more than working tree. For example, if you're checked out on main in one tree, and then try to check it out in another tree too you'll get an error something like the following:
$ git worktree add ../linked main
fatal: 'main' is already checked out at 'C:/repos/app-example/_'
Preparing worktree (checking out 'main')
Similarly, if you try to switch to a branch that's checked-out in a different working tree, you'll get an error:
$ git switch bug-fix
fatal: 'bug-fix' is already checked out at 'C:/repos/app-example/linked'
These are pretty minor issues generally, with obvious resolutions, they're just something to be aware of. The biggest downside is the cognitive overhead of having two folders associated with the same clone, but if you find yourself in need of it, I think git worktree can be a very handy solution.
Summary
In this post I described several git scenarios in which you need to switch branches back and forth. If you're in the middle of a big refactor or complex work then handling this scenario can be frustrating. git worktree provides an alternative solution to the problem, but allowing you to have additional a different branch checked-out in another folder, and "linking" the working tree to your repository. I have found this useful when I'm working on two separate feature branches simultaneously, though it does come with some cognitive overhead, so I only tend to use it in these "long running branch" scenarios.