I recently needed an algorithm to count the number of leading zeroes in a ulong value. In this post I describe the algorithm I used and demonstrate how it works.
The requirements: count the leading zeros in a long value
In my work on the Datadog APM tracer, I recently needed to know the number of "leading zeroes" of a ulong value, in order to encode it efficiently. So for the 64-bit long value 24,649 (shown below in binary) the number of leading zeroes is 49
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0110 0000 0100 1001
^First non-zero bit
In .NET Core 3.0, there's an API that gives you this value directly: BitOperations.LeadingZeroCount()
using System.Numerics;
ulong value = 24_649;
int zeroes = BitOperations.LeadingZeroCount(value); // 49
This API maps directly to CPU intrinsic instructions, so it's very efficient.
Unfortunately, we also need to support .NET Framework, .NET core 2.1, and .NET Standard 2.0, so we needed an algorithm that would work everywhere. After taking a trip to Stack Overflow we found the following loop-free and conditional-free algorithm that achieves the same thing.
The "smear and count" algorithm
The algorithm we used was based on the one in this Stack Overflow answer, which uses a two-step approach:
- "Smearing" (mark all the bits to the right of the most significant set bit)
- Counting the number of 1s
The final code we used (when BitOperations was not supported) is the following (we'll go through this code carefully for the rest of this post)
private static uint NumberOfLeadingZerosLong(ulong x)
{
// Do the smearing which turns (for example)
// this: 0000 0101 0011
// into: 0000 0111 1111
x |= x >> 1;
x |= x >> 2;
x |= x >> 4;
x |= x >> 8;
x |= x >> 16;
x |= x >> 32;
// Count the ones
x -= x >> 1 & 0x5555555555555555;
x = (x >> 2 & 0x3333333333333333) + (x & 0x3333333333333333);
x = (x >> 4) + x & 0x0f0f0f0f0f0f0f0f;
x += x >> 8;
x += x >> 16;
x += x >> 32;
const int numLongBits = sizeof(long) * 8; // compile time constant
return numLongBits - (uint)(x & 0x0000007f); // subtract # of 1s from 64
}
If you can understand how that code works just by looking at it, that's impressive! I ran some sense checks to confirm that this algorithm gives the same answer as BitOperations.LeadingZeroCount(), but it bugged me that I didn't fully understand how. In this post, I go through each stage to properly understand it.
I use a worked example in this post, using the (randomly selected) number 24,649 shown in the previous section.
We'll start with the "smearing" part of the code first. Thankfully this part is relatively simple.
Smearing
The "smearing" part of the algorithm is the process of changing every bit to the right of the left-most 1 to 1, for example:
Before: 0010 0100
After: 0011 1111
This smearing is achieved with a series or right-shifts and bitwise-OR:
x |= x >> 1;
x |= x >> 2;
x |= x >> 4;
x |= x >> 8;
x |= x >> 16;
x |= x >> 32;
Let's work through the example of 24,649. The first step is a single bit shift and OR:
x 0000 ... 0000 0000 0110 0000 0100 1001
x >> 1 0000 ... 0000 0000 0011 0000 0010 0100
x |= x >>1 0000 ... 0000 0000 0111 0000 0110 1101
Flipped ^ ^ ^
If you compare the original x with the result of the bit shift and OR, you can see the result is that every 0 to the right of a 1 has been flipped. Lets go to the next step, shifting two bits to the right, and bitwise-OR. As before, the pattern continues, flipping 0 bits to the right of 1s. Note that after the first step, we know that set bits come in pairs (11) at the least, which is why we can shift twice:
x 0000 ... 0000 0000 0111 0000 0110 1101
x >> 2 0000 ... 0000 0000 0001 1100 0001 1011
x |= x >>2 0000 ... 0000 0000 0111 1100 0111 1111
Flipped ^^ ^ ^
For the third step, the smallest 1 run size is four (1111), so we shift right 4 bits, and OR:
x 0000 ... 0000 0000 0111 1100 0111 1111
x >> 4 0000 ... 0000 0000 0000 0111 1100 0111
x |= x >>2 0000 ... 0000 0000 0011 1111 1111 1111
Flipped ^^ ^
Our example is now completely smeared—every bit to the right of the leftmost 1 is now set to 1. To be sure we can handle every value, we need to do the shift-and-OR three more times, but the pattern continues, so we'll move on to the next part of the algorithm for now.
Counting the number of 1s
After the smearing stage, the number of leading-zeros is the same as 64 (the number of bits) minus the number of 1s. The final stage of the algorithm exploits this by using an efficient process to count the number of 1s in the smeared number.
Specifically, the algorithm (based on the Stack Overflow answer) uses:
a variable-precision SIMD within a register (SWAR) algorithm to perform a tree reduction adding the bits in a 32-bit value
which means nothing to me!😂
To recap, this part of the algorithm is shown below. I'll step through each of these lines one-by-one afterwards to understand what they're doing:
// Count the ones
x -= x >> 1 & 0x5555555555555555;
x = (x >> 2 & 0x3333333333333333) + (x & 0x3333333333333333);
x = ((x >> 4) + x) & 0x0f0f0f0f0f0f0f0f;
x += x >> 8;
x += x >> 16;
x += x >> 32;
return numLongBits - (uint)(x & 0x0000007f); // subtract # of 1s from 64
Well start by taking the first line x = x - (x >> 1 & 0x5555555555555555), where x starts as the value at the end of the smearing stage (which we produced using the test value 24,649). There's a lot happening in this first line, which consists of a bit-shift right, a bitwise AND with the alternating 01010101 pattern, and finally subtraction from the original x value. The final value of x is given by the stage E below:
A| x | 0000 ... 0000 0000 0111 1111 1111 1111
B| x >> 1 | 0000 ... 0000 0000 0011 1111 1111 1111
C| 0x555555 | 0101 ... 0101 0101 0101 0101 0101 0101
D| B & C | 0000 ... 0000 0000 0001 0101 0101 0101
E| A - D | 0000 ... 0000 0000 0110 1010 1010 1010
So what's the final result of this stage? It may not be entirely obvious, but this stage has effectively done a "sum" between pairs of bits in the original x value. So when a bit pair was 11, the result is 10 (binary for "2"). When the bit pair is 01, the result is 01 (binary for "1"), and for 00 it's 00.

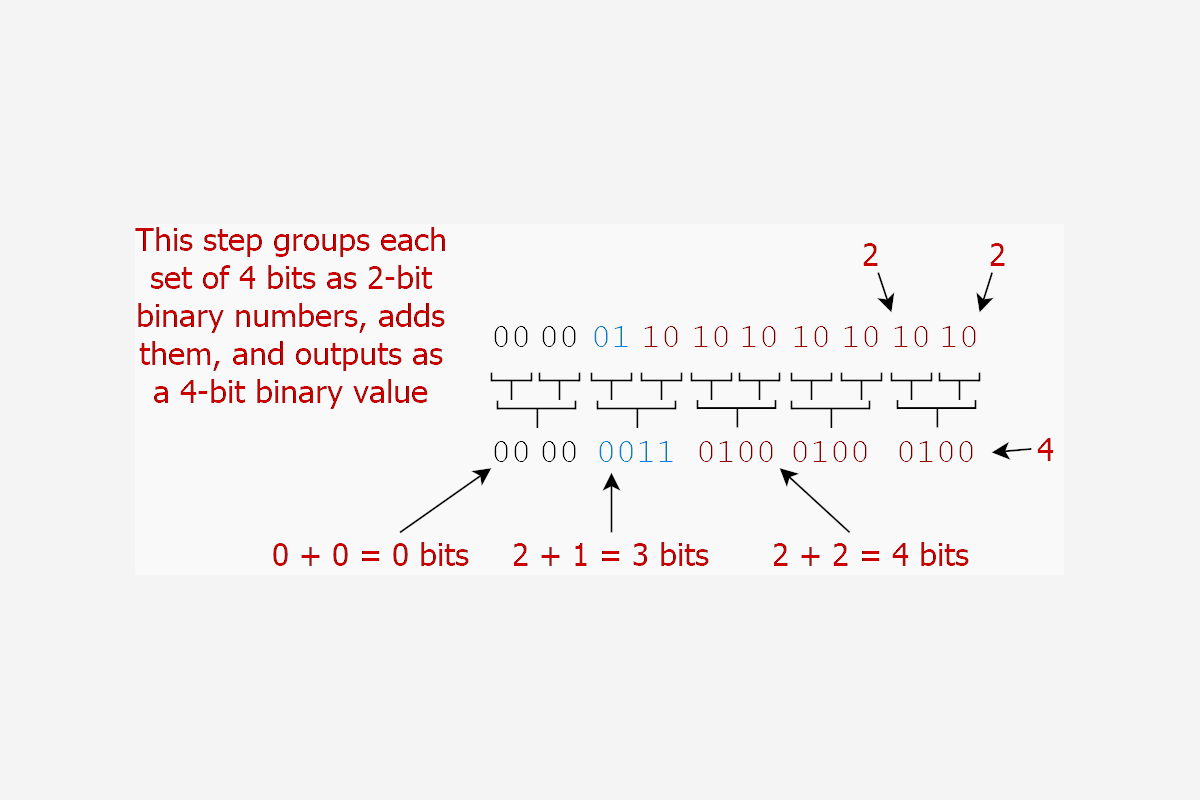
So the first line accumulates pairs of bits. The second line of the algorithm is also complex to read: x = (x >> 2 & 0x3333333333333333) + (x & 0x3333333333333333). Instead of counting individual bits, this line adds pairs of bits (in binary), and outputs the 4-bit result. The 0x33333 value is another alternating pattern, 00110011, which selects 2 bits at a time. The output J below is the final result for this line:
E. x 0000 ... 0000 0000 0110 1010 1010 1010
F. x >> 2 0000 ... 0000 0000 0001 1010 1010 1010
G. 0x333333 0011 ... 0011 0011 0011 0011 0011 0011
H. F & G 0000 ... 0000 0000 0001 0010 0010 0010
I. A & G 0000 ... 0000 0000 0010 0010 0010 0010
J. H + I 0000 ... 0000 0000 0011 0100 0100 0100
So this stage has grouped "pairs" of bits into nibbles of 4 bits, added the upper 2-bit number to the bottom 2-bit number, and saved the output in the 4 bits:

The third line is similar, adding together 4-bit pairs of number and outputting to 8-bit groups x = ((x >> 4) + x) & 0x0f0f0f0f0f0f0f0f.
J. x 0000 ... 0000 0000 0011 0100 0100 0100
K. x >> 4 0000 ... 0000 0000 0000 0011 0100 0100
L. J + K 0000 ... 0000 0000 0011 0111 1000 1000
M. 0x0f0f0f 0000 ... 0000 1111 0000 1111 0000 1111
N. L & M 0000 ... 0000 0000 0000 0111 0000 1000
Visually, this is similar to the previous step:

On the fourth line of the algorithm, things get a bit easier to understand x = x + x >> 8. Up to this point, we've been doing binary arithmetic on sub-byte numbers of bits, so we had to do it manually. But now we can fallback to simpler manipulation, so things get a lot easier.
Before line 4, each 8-bit byte contains the number of 1s that were present. The final lines add them all up by shifting all the bits down to the lowest byte and adding them together:
O. x 0000 ... 0000 0000 0000 0111 0000 1000
P. x >> 8 0000 ... 0000 0000 0000 0000 0000 0111
Q. x + x >> 8 0000 ... 0000 0000 0000 0111 0000 1111
Once that's all done, the final 8 bits contains the number of 1 bits set in the smeared result, 0000 1111 = 15. To find the number of leading 0s, we subtract 15 from the number of bits in a ulong, and we get 64-15 = 49.
If we check the result with BitOperations.LeadingZeroCount(), we'll see it gets 49 too. Hooray! We now have an implementation we can use in pre-.NET Core 3.0 targets. But the question is, how does this algorithm compare to the "native" implementation, as well as a "naïve" implementation?
Benchmarking against the alternatives
To test the performance of the Smear and count algorithm I compared it to the gold standard (the BitOperations.LeadingZeroCount() method that uses CPU intrinsics), and to a naïve implementation that shifts the ulong repeatedly until the top bit is set.
I created a .NET 6 benchmarking project using:
dotnet new console
dotnet add package BenchmarkDotNet
I added three benchmarks to the project:
BitOps—uses theBitOperations.LeadingZeroCount()methodManualCount—tests the top bit for1and bit shiftsSmearAndCount—uses the algorithm in this post.
Each algorithm is tested with two values, the 24,649 value we've used throughout this post, and the value 288,230,513,657,774,080, which in binary looks like this:
0100_0000_0000_0000_0000_0010_0000_0000_0100_0000_0000_0000_0000_0000_0000
^
which has a 1 very close to the left.
The final Program.cs file looks like this:
using System.Numerics;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
BenchmarkRunner.Run<LeadingZeroes>();
public class LeadingZeroes
{
const int numLongBits = sizeof(long) * 8; // compile time constant
[Params(24_649, 288_230_513_657_774_080)]
public ulong TestValue { get; set; }
[Benchmark(Baseline = true)]
public int BitOps() => BitOperations.LeadingZeroCount(TestValue);
[Benchmark]
public int ManualCount()
{
const ulong testBit = 0b1000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000_0000;
var x = TestValue;
for (int i = 0; i < numLongBits; i++)
{
if (unchecked(x & testBit) != 0)
{
return i;
}
x = x << 1;
}
return 0;
}
[Benchmark]
public uint SmearAndCount()
{
var x = TestValue;
// smear
x |= x >> 1;
x |= x >> 2;
x |= x >> 4;
x |= x >> 8;
x |= x >> 16;
x |= x >> 32;
// Count the ones
x -= x >> 1 & 0x5555555555555555;
x = (x >> 2 & 0x3333333333333333) + (x & 0x3333333333333333);
x = (x >> 4) + x & 0x0f0f0f0f0f0f0f0f;
x += x >> 8;
x += x >> 16;
x += x >> 32;
return numLongBits - (uint)(x & 0x0000007f); // subtract # of 1s from 64
}
}
So what are the results?
BenchmarkDotNet=v0.13.2, OS=Windows 10 (10.0.19043.1889/21H1/May2021Update)
Intel Core i7-8750H CPU 2.20GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores
.NET SDK=6.0.303
[Host] : .NET 6.0.8 (6.0.822.36306), X64 RyuJIT AVX2
DefaultJob : .NET 6.0.8 (6.0.822.36306), X64 RyuJIT AVX2
| Method | TestValue | Mean | Error | StdDev |
|---|---|---|---|---|
| BitOps | 24649 | 0.0148 ns | 0.0126 ns | 0.0105 ns |
| ManualCount | 24649 | 18.3968 ns | 0.3831 ns | 0.4982 ns |
| SmearAndCount | 24649 | 2.7582 ns | 0.0412 ns | 0.0365 ns |
| BitOps | 288230513657774080 | 0.0000 ns | 0.0000 ns | 0.0000 ns |
| ManualCount | 288230513657774080 | 3.0473 ns | 0.0543 ns | 0.0481 ns |
| SmearAndCount | 288230513657774080 | 2.7358 ns | 0.0189 ns | 0.0167 ns |
So from this you can take that BitOperations.LeadingZeroCount is blindingly fast, as you might expect, given it uses CPI intrinsics. As for the Smear and Count described in this post, we're still impressively fast, coming in at sub 3ns, and that's consistent no matter which value we use. In contrast, the "manual" approach is heavily dependent on the number being tested. I was personally impressed that the Smear and Count is faster than the manual approach, even when the zero count is only 1!
Summary
In this post I described an algorithm that counts the number of leading zeros in a ulong value. There is a built-in function for this in .NET Core 3.0+, BitOperations.LeadingZeroCount(), which is incredibly fast as it uses CPU intrinsic functions. But if you need to support older frameworks too, you need to use a different approach.
The algorithm in this post first "smears" the set bits in a number, so that every value after the left-most 1 is also set to 1. It then counts the number of set bits by using a tree-like approach, grouping into successively larger groups of bits until all the values are counted. In benchmarks, this approach consistently returns in sub-3ns, not as fast as the intrinsic approach, but much faster than a "manual" approach would be.