In this post I describe some important things to think about when designing your incremental source generator, particularly the pitfalls to watch out for. This post is somewhat of a summary of my experience building source generators for the last 2 years, and focuses on making your source generator as performant as possible.
I'm not going to cover the basics of creating an incremental source generator in this post; if source generators are knew to you, I suggest reading the earlier posts in this series. For a more formal discussion, you can also read the docs in the Roslyn repository.
I recently updated the first post in the series to follow these rules. At the time I originally wrote the post, I wasn't aware of the limitations, so if you followed that tutorial for your own generators, I suggest taking another look after you've read this post!
These are the main guidelines I explain in this post:
- Use the .NET 7 API
ForAttributeWithMetadataName. - Don't use
*SyntaxorISymbolinstances in your pipeline. - Use a value type data model (or
records, or a custom comparer). - Watch out for collection types.
- Be careful using
CompilationProvider. - Take care with
Diagnostics - Consider using
RegisterImplementationSourceOutputinstead ofRegisterSourceOutput.
Before we get to those, it's important to understand exactly what we mean when we say the "performance" of source generators.
What does performance mean for a source generator?
One important clarification when we discuss the "performance of source generators" is that we're not talking about the performance of the generated code. The runtime performance of the code you generate is entirely tangential to this discussion, and is subject to the same limitations and constraints as any code you write.
What we're talking about is the impact of your source generator on your IDE. Source generators typically execute every time you type in your IDE editor, often before you even save the file i.e. a lot 😅. Because of that, it's important to minimize the work they have to do. If you have a lot of badly written source generators in a solution you may find your IDE grinds to a halt with every key press!
You may wonder if the performance of your source generators impact compile times. I would be less concerned about this, as your generator will likely only run once in that case. The IDE scenario is really the crucial one.
With that in mind, you should be sure to write "generic" performant code where possible. There is always some low-hanging performance fruit like using foreach instead of LINQ; every little reduction in allocations will help the IDE that's running your code many times a second.
But the real gains come from using the right APIs, and being mindful of how incremental generators do caching. Those points are the focus of this post.
This post is entirely focused on the
IIncrementalGeneratorgenerator, introduced in .NET 6. You should never be using the olderISourceGeneratorAPI.
Understanding when your source generator runs
The first thing to understand about incremental generators is when the different methods run.
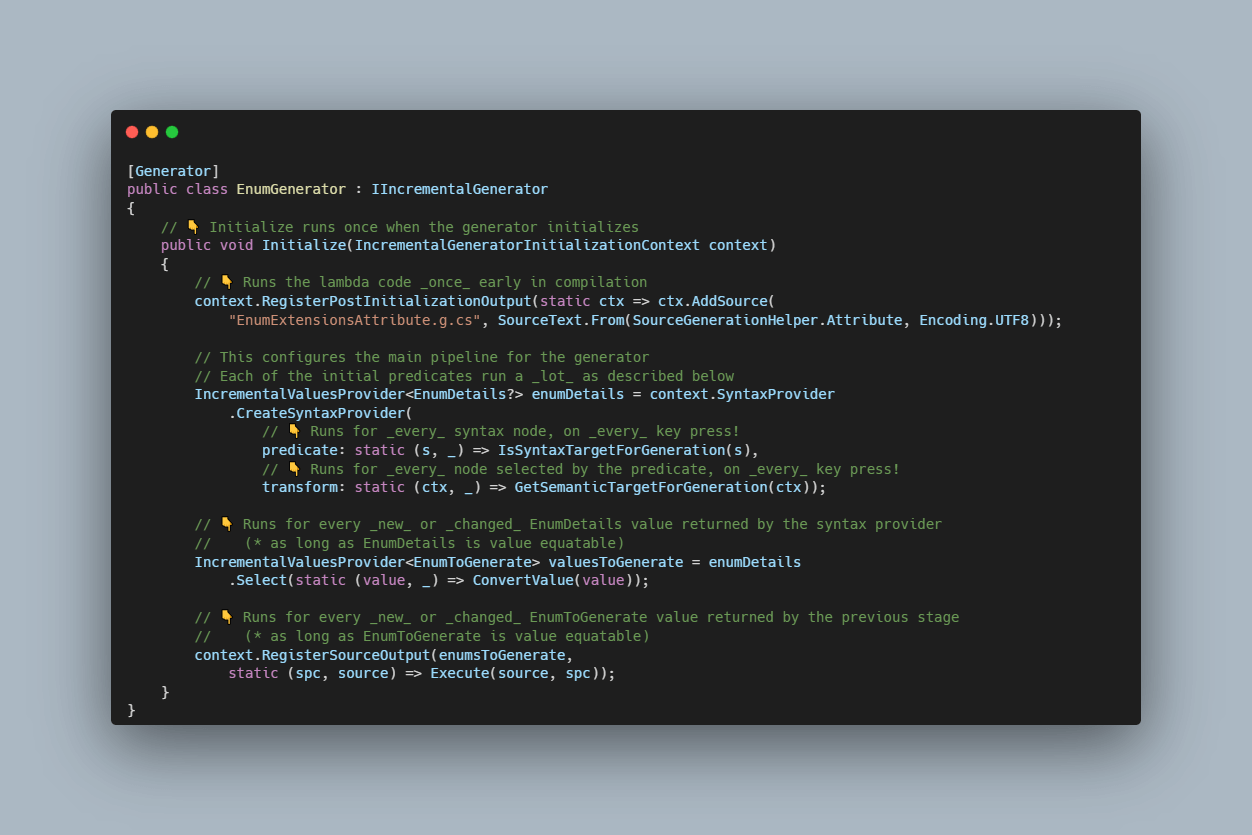
Lets take this simple generator, which is based on the tutorial from the first post in this series. I've annotated each of the important method calls to indicate when they're called (as I understand it!)
[Generator]
public class EnumGenerator : IIncrementalGenerator
{
// 👇 Initialize runs once when the generator initializes
public void Initialize(IncrementalGeneratorInitializationContext context)
{
// 👇 Runs the lambda code _once_ early in compilation
context.RegisterPostInitializationOutput(static ctx => ctx.AddSource(
"EnumExtensionsAttribute.g.cs", SourceText.From(SourceGenerationHelper.Attribute, Encoding.UTF8)));
// This configures the main pipeline for the generator
// Each of the initial predicates run a _lot_ as described below
IncrementalValuesProvider<EnumDetails?> enumDetails = context.SyntaxProvider
.CreateSyntaxProvider(
// 👇 Runs for _every_ syntax node, on _every_ key press!
predicate: static (s, _) => IsSyntaxTargetForGeneration(s),
// 👇 Runs for _every_ node selected by the predicate, on _every_ key press!
transform: static (ctx, _) => GetSemanticTargetForGeneration(ctx));
// 👇 Runs for every _new_ EnumDetails value returned by the syntax provider
// (* as long as EnumDetails is value equatable)
IncrementalValuesProvider<EnumToGenerate> valuesToGenerate = enumDetails
.Select(static (value, _) => ConvertValue(value));
// 👇 Runs for every _new_ EnumToGenerate value returned by the syntax provider
// (* as long as EnumToGenerate is value equatable)
context.RegisterSourceOutput(enumsToGenerate,
static (spc, source) => Execute(source, spc));
}
}
The most important points here are:
- The syntax provider
predicateruns once for every syntax node in your project, every time syntax changes (i.e. every time a key is pressed)! - The syntax provider
transformis run once for every syntax node that thepredicateselects, every time syntax changes (i.e. every time a key is pressed)! IncrementalValuesProvider<T>caches values and only runs subsequent stages if a value changes (or there's a new value).
Based on these points, we have some high level rules:
- The
predicatemust be fast to execute (i.e. it should ideally rely on syntax only and not the semantic model) because it executes so often. - The
predicatemust also be highly selective, as any node that passes will run thetransform(on every keypress). In general, this conflicts with point 1, so there will inevitably be some trade-offs there! - All values used in
IncrementalValuesProvider<T>must be comparable for equality, so they are cacheable. Note that by default, if you useclass,SyntaxorISymboltypes in yourIncrementalValuesProvider<>you will likely not get any caching!
Understanding these points is key to all the subsequent performance tips in this post! I'll expand on each of these in each subsequent section.
1. Use the .NET 7 API ForAttributeWithMetadataName
One of the most common patterns with source generators is to create an attribute that "drives" the source generation. The EnumExtensions generator described in this series uses this pattern, as do most of the "built-in" generators that now come with .NET.
This pattern is so common that in .NET 7 they added a new API called ForAttributeWithMetadataName that massively optimises this scenario. I've seen various quotes that this can remove 99% of the number of nodes your code ends up evaluating. And it's not just that your code doesn't run—roslyn itself has less work to do as it doesn't need to materialize SyntaxNodes or check semantic information!
When I originally created this series, I was using the .NET 6 release, which is why I don't use
ForAttributeWithMetadataNamein the original example, but I always suggest you use it now where possible.
To use ForAttributeWithMetadataName you must be using the .NET 7+ SDK (it won't work with the .NET 6 SDK), and you must use version 4.4.0+ of Microsoft.CodeAnalysis.CSharp:
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.4.0" PrivateAssets="all" />
</ItemGroup>
Changing your existing code to use the new API is pretty simple. At the first stage of your generator, instead of calling CreateSyntaxProvider(), use ForAttributeWithMetadataName(), providing the full metadata name of your attribute (excluding the assembly), and your predicate and transform code:
IncrementalValuesProvider<EnumDetails?> enumsToGenerate = context.SyntaxProvider
.ForAttributeWithMetadataName( // 👈 use the new API
"NetEscapades.EnumGenerators.EnumExtensionsAttribute", // 👈 The attribute to look for
predicate: (node, _) => node is EnumDeclarationSyntax, // 👈 A basic predicate, may not be necessary
transform: static (ctx, _) => GetSemanticTargetForGeneration(ctx)); // 👈 The original transform
Depending on how your attribute is defined (with AttributeUsage), you may find your predicate can be as simple as (_, _) => true, as it's guaranteed to always be a node decorated with that attribute!
2. Don't use *Syntax or ISymbol instances in your pipeline
A very common mistake in a lot of source generators is returning SyntaxNode or ISymbol instances from calls to CreateSyntaxProvider() and other APIs. In general, if you ever have these types as the T in an IncrementalValuesProvider<T>, then your caching is probably broken, and generator is doing much more work than it should:
// ⚠ This shows an example of the _incorrect_ behaviour!
// A *Syntax type in IncrementalValuesProvider<T> should ring alarm bells!
// 👇
IncrementalValuesProvider<EnumDeclarationSyntax> enumsToGenerate = context.SyntaxProvider
.ForAttributeWithMetadataName(
"NetEscapades.EnumGenerators.EnumExtensionsAttribute",
predicate: (node, _) => node is EnumDeclarationSyntax,
transform: static (ctx, _) => ctx.Node); // 😱 oh no, returning the syntax node!
This is a mistake I made myself when first writing incremental source generators. It looks like you're doing the right thing, as you're delaying work till later, but this completely breaks any caching, so the next stages will always run.
The problem is that the SyntaxNodes are classes that are created anew with every change to a file, and hence execution of your source generator. So every SyntaxNode you return is considered "new" by the caching mechanism, even if it logically represents the same syntax node in the project. So you bypass the cache, and end up doing a lot more work later on.
Technically
SyntaxNodesaren't strictly always problematic, as they're sometimes equatable. Nevertheless, it's safest to not use them if you can possibly help it.ISymbols are never equatable, so you should never return them.
So if you shouldn't return SyntaxNodes or ISymbol like this, what should you do?
3. Use a value type data model (or records, or a custom comparer)
The key thing to establish is that you should use a "data model" that's completely separate from the roslyn APIs. Each type in the data model should ideally be comparable by value so that caching can compare instances.
By a "data model", I mean a hierarchy of
struct,class, orrecords that contains the details you need from the syntax nodes, but otherwise uses only simple types.
As a concrete example, I used a simple one-type data model for the EnumExtensions generator earlier in this series:
public readonly record struct EnumToGenerate
{
public readonly string Name;
public readonly EquatableArray<string> Values;
public EnumToGenerate(string name, List<string> values)
{
Name = name;
Values = new(values.ToArray());
}
}
The important thing about this type is that if you have two instances of EnumToGenerate with the same Name and Values, then enum1.Equals(enum2) would return true. Value types generally have these semantics, but I typically also use records as they automatically implement IEquatable<T>.
Just to reiterate, the key is to extract all the details you need from the SyntaxNode and SemanticModel in the syntax provider transform, and store these in a data model that is equatable so that caching works correctly.
Technically you can pass a custom comparer for comparing types
Tby callingWithComparer(), but I think making your types inherently comparable is overall safer and potentially easier.
You may have noticed in the example above that I used a type EquatableArray<T>. That's because virtually all the collection types in .NET don't implement structural equality, which means they break caching if you use them in your data model!
4. Watch out for collection types
As discussed in points 2 and 3, the types in your data model need to be compared by value in almost all cases. If your data model includes a collection, that means the collection must also be comparable by value i.e. if all the items inside the collection are equal, then the collection itself should be considered equal. Unfortunately, most of the collection types in .NET don't provide this guarantee.
Even the
ImmutableArray<T>struct, which implementsIEquatable<T>, only checks if each instance wraps the same underlying array, not whether the contents of the two different arrays are equal.
The solution (unfortunately) is to create your own type that does have the semantics you want. This is something I add to basically every source generator I create. They are all based on this implementation from the .NET Community Toolkit, which does the job perfectly.
One slight annoyance is implementing GetHashCode(). The "easy" way to do that is to use the HashCode type that was introduced in .NET 6. Unfortunately, as source generators must target netstandard2.0 you can't use HashCode🙄 That means I also always end up adding a stripped down version of the HashCode type just to use it in EquatableArray<T>🤷♂️
As long as you're careful about always using value types and records, and EquatableArray<T> for collections, then you should be in a good place for caching.
5. Be careful using CompilationProvider
Using SyntaxProvider is the most common API you'll use in source generators, but there is also a CompilationProvider you can use to access the Compilation:
IncrementalValueProvider<Compilation> compilation = context.CompilationProvider;
You can use this to get all sorts of details about the compilation itself—the assembly being created, assembly references, syntax trees, standard types—all sorts of things! However, you should pretty much never combine the output of the CompilationProvider with your "normal" pipeline, for example:
// This part is ok
IncrementalValuesProvider<EnumDetails?> enumsToGenerate = context.SyntaxProvider
.ForAttributeWithMetadataName(
"NetEscapades.EnumGenerators.EnumExtensionsAttribute",
predicate: (node, _) => node is EnumDeclarationSyntax,
transform: static (ctx, _) => GetSemanticTargetForGeneration(ctx));
// Not problematic on it's own...
IncrementalValueProvider<Compilation> compilation = context.CompilationProvider;
// ⚠😱 Don't do this!
IncrementalValuesProvider<(EnumToGenerate? Left, Compilation Right)> combined
= enumsToGenerate.Combine(compilation); // 👈 Combining with `Compilation`
context.RegisterSourceOutput(combined, static (spc, pair) => {});
The problem here is that while enumsToGenerate is using efficient APIs to avoid work, and is using a record struct data model to aid caching, we're later losing all those benefits by combining with the Compilation.
The CompilationProvider emits a new Compilation every time the compilation changes, which, again, means every time you type in the IDE! That means in the example above, RegisterSourceOutput will also be called every time you type in your IDE 😬
Instead of combining with Compilation directly, you should call Select() to obtain a cacheable data model. For example, in the following I extract the assembly name, which is easily cacheable.
// Always extract a data model from the `Compilation`
IncrementalValueProvider<string?> assemblyNames =
// 👇 This will run with every key press, but it's lightweight
context.CompilationProvider.Select((c, _) => c.AssemblyName);
// Each of the value providers, enumsToGenerate and assemblyNames are
// heavily cached, so this will only emit when one of them changes,
// _not_ on every key press
IncrementalValuesProvider<(EnumToGenerate? Left, string? Right)> combined =
enumsToGenerate.Combine(assemblyNames);
This example also demonstrates the general rule that "more layers" in your pipeline means more opportunities for caching.
6. Take care with Diagnostics
When you're building a production-level source generator, you'll inevitably want to produce Diagnostics to warn consumers about incorrect usages. However, Diagnostic instances can be tricky as they can easily do things like wrap ISymbol instances, which as we've already discussed, will break incrementality.
There are a couple of approaches you can take to handling this:
- The safest approach is to write a separate analyzer that outputs the diagnostics instead of doing it from your generator.
- Alternatively, you can extract all the information you need to output diagnostics. And just like the rest of your data model, you must make sure it's all cacheable.
The first approach is likely the recommended one, but frankly it's a lot more effort. Consequently, I've always favoured the latter approach. For me, that typically consists of three things:
- A
Result<T>"discriminated union" type returned from the generator stages. - A
DiagnosticInforecord that captures all the information you need to create aDiagnosticlater. In my implementation, this contains of aDiagnosticDescriptorand aLocationInforecord - The
LocationInfotype is a simple record that captures the important features of theLocationtype (asLocationisn't directly equatable as far as I can tell).
There's nothing very special about these types, but they mean I can be sure everything is correctly cacheable. We'll start with the Result<T> type:
internal sealed record Result<TValue>(TValue value, EquatableArray<DiagnosticInfo> errors)
where TValue : IEquatable<TValue>?
{
}
This type potentially holds an extracted value, as well as one or more DiagnosticInfo types, shown below:
internal sealed record DiagnosticInfo
{
// Explicit constructor to convert Location into LocationInfo
public DiagnosticInfo(DiagnosticDescriptor descriptor, Location? location)
{
Descriptor = descriptor;
Location = location is not null ? LocationInfo.CreateFrom(location) : null;
}
public DiagnosticDescriptor Descriptor { get; }
public LocationInfo? Location { get; }
}
The DiagnosticDescriptor type is a standard type that parts of the Microsoft.CodeAnalysis package. It implements IEquatable<DiagnosticDescriptor>, so it should be safe to use here.
The LocationInfo type is shown below, and is meant to encapsulate the important information from the Location type, such that we can reconstruct an appropriate Location later. It's a simple record, with some helpers for converting to and from a Location:
internal record LocationInfo(string FilePath, TextSpan TextSpan, LinePositionSpan LineSpan)
{
public Location ToLocation()
=> Location.Create(FilePath, TextSpan, LineSpan);
public static LocationInfo? CreateFrom(SyntaxNode node)
=> CreateFrom(node.GetLocation());
public static LocationInfo? CreateFrom(Location location)
{
if (location.SourceTree is null)
{
return null;
}
return new LocationInfo(location.SourceTree.FilePath, location.SourceSpan, location.GetLineSpan().Span);
}
}
With these helper types, you should be safer to produce diagnostics from your generator without breaking your pipeline. If you do, make sure to "split off" your diagnostics in a separate pipeline, so they don't impact the incrementality of the rest of your generator.
7. Consider using RegisterImplementationSourceOutput instead of RegisterSourceOutput
The final performance tip I have is related to the RegisterImplementationSourceOutput() method. This is something I haven't actually used yet, but I have had my eye on as potentially a big win.
This method essentially does the same thing as RegisterSourceOutput(). The difference is that it guarantees that the code you're generating won't change the semantic meaning of the rest of the code.
What does that mean? Well, If the generated code doesn't change the semantic meaning, then it means the rest of your code will still compile "the same" way—i.e. you won't get red squiggly lines in your IDE—whether the generator runs or not. That means the IDE can potentially put-off running the generator entirely until it actually needs to do the final compilation. That could potentially save a huge amount of work.
I'm not sure if IDEs actually take advantage of this optimisation or not, so this one is definitely speculative! If you know if it makes a big difference, I'd definitely be interested to know the details.
There's really only one case where you should use this method, when the generated code is not going to be directly referenced. If the code will only be invoked from native or external APIs for example, then it may make sense to use RegisterImplementationSourceOutput.
Originally, I thought
RegisterImplementationSourceOutputmight also work if you're generating partial methods or interceptor implementations, but that might cause IDE errors, so it should probably be avoided.
Like I say, I haven't actually used this method, but I have my eye on a couple of generators at work that may benefit from this!
Bonus: Don't use reflection
My final bonus tip isn't strictly about performance, it's more about correctness. I've seen a couple of source generators that use "normal" reflection APIs to try to get details about types, and then trying to use them in the generator output.
The reason this is almost certainly not what you want to do, is that using reflection APIs is doing reflection over the compiler/IDE host's runtime, not over the target application's runtime. So you might be loading types that won't exist in the target runtime, and getting yourself into a confusing mess!
That brings us to the end of this post on performance. It's well overdue and if you've implemented any source generators, I strongly recommend going back and taking a look at your implementation. If nothing else, make sure you're using ForAttributeWithMetadataName and a record-based data model!
Summary
In this post I discussed IDE performance for incremental source generators. I first described how often various methods in your source generator are executed, so you know what you're optimising. I then described 6 things to keep in mind when building source generators. The most important takeaways were: use the .NET 7 SDK API ForAttributeWithMetadataName() if possible; and use a record-based data model, taking care with collections.