In my previous post, I took a first look at the internal design of StringBuilder class, and we looked at the source code behind the constructors and Append(char) methods. In this post we take a look at more of those methods.
This post follows on directly from the previous post, so I won't do a recap here. If you haven't read the previous post yet, I suggest you do that now, to get a better understanding of the overall design, as well as the details of the internal fields etc.
In this post we look at appending three different types: strings, built in types (like int and double), and lists (with a separator)
Appending strings
In the previous post, I showed how a single char and a single repeated char are added to the StringBuilder. Next we'll look at how a string is added, though for simplicity (to avoid going through too many overloads), we'll look at the overload in which you provide a startIndex and a count too:
public StringBuilder Append(string? value, int startIndex, int count)
{
unsafe
{
fixed (char* valueChars = value)
{
Append(valueChars + startIndex, count);
return this;
}
}
}
Once you remove all the precondition checks, the resulting function is remarkably small, though it is likely rather unfamiliar if you haven't done any "low-level" programming in C#, as it uses the unsafe and fixed keywords!
The unsafe keyword, as the name suggests, moves you from the default "safe" context of C#, to a dangerous land in which you can work with raw pointers. If you've ever written any C++ then you'll be familiar with pointers. A pointer variable contains the memory address of another variable, and is denoted by a * suffix. So a char* variable contains the memory address of a char variable.
Now, C# has a managed runtime, which usually takes care of memory management, managing all those pointers for you. Of particular concern is the Garbage Collector, which is free to move the location of variables in memory, to make better use of the available space. This is a problem in unsafe code, as you can't guarantee that the pointer to a reference type variable will still point to the first variable after a GC happens. To work around that, you can use the fixed statement to say "don't move this variable". While the variable is "pinned", the GC won't relocate the object.
So, back to Append(). After the precondition checks (not shown) the method enters an unsafe context, and allocates a char* pointer to the string value we were provided. This pointer points to the first char in the underlying char[] of the string, and is fixed, so the GC won't move the value object.
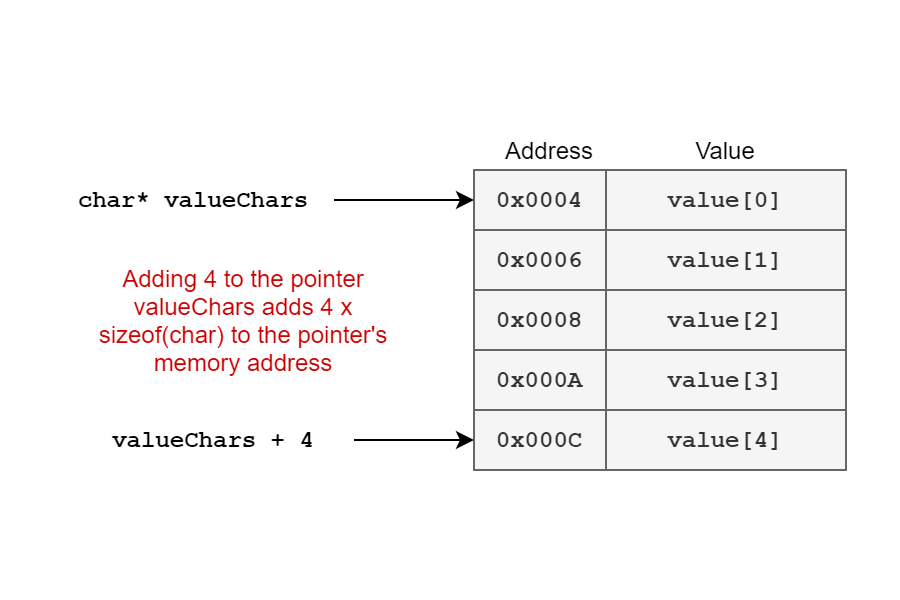
Next, we do a bit of pointer arithmetic. Again, for C/C++ this is all pretty standard, but C# devs generally don't need to do it! Pointer arithmetic relies on the fact that an array in C# is laid out sequentially in memory. For example, if value[0] has memory address 0x0004, and each array entry takes up 2 bytes of memory then, char[1] will have memory address 0x0006, and value[2] will have memory address 0x0008 etc.

Given that char* valueChars points to value[0], valueChars + startIndex will point to element value[startIndex].
Note that the actual physical memory addresses incremented depends on the size (in bytes) of the underlying type in the array when doing pointer arithmetic. For a
char, wheresizeof(char)=2, incrementing the pointer by 3 increments the address by3x2=6.
The method ends by calling Append(char* value, int valueCount), which is where the heavy lifting is done.
internal char[] m_ChunkChars;
internal int m_ChunkLength;
internal int m_MaxCapacity;
public unsafe StringBuilder Append(char* value, int valueCount)
{
int newLength = Length + valueCount;
if (newLength > m_MaxCapacity || newLength < valueCount)
{
throw new ArgumentOutOfRangeException(nameof(valueCount), SR.ArgumentOutOfRange_LengthGreaterThanCapacity);
}
// This case is so common we want to optimize for it heavily.
int newIndex = valueCount + m_ChunkLength;
if (newIndex <= m_ChunkChars.Length)
{
new ReadOnlySpan<char>(value, valueCount).CopyTo(m_ChunkChars.AsSpan(m_ChunkLength));
m_ChunkLength = newIndex;
}
else
{
// Copy the first chunk
int firstLength = m_ChunkChars.Length - m_ChunkLength;
if (firstLength > 0)
{
new ReadOnlySpan<char>(value, firstLength).CopyTo(m_ChunkChars.AsSpan(m_ChunkLength));
m_ChunkLength = m_ChunkChars.Length;
}
// Expand the builder to add another chunk.
int restLength = valueCount - firstLength;
ExpandByABlock(restLength);
// Copy the second chunk
new ReadOnlySpan<char>(value + firstLength, restLength).CopyTo(m_ChunkChars);
m_ChunkLength = restLength;
}
return this;
}
We start the method by calculating what the new length of the string will be, and ensuring that it won't exceed the maximum capacity defined in m_MaxCapacity. The newLength < valueCount check also catches any integer overflow issues.
Next, as described in the code comment, we check for the common situation where there is enough empty space left in the m_ChunkChars buffer to fit the requested number of characters. In that situation we can wrap a ReadOnlySpan<char> around the memory pointed to by the char*, copy the values directly into m_ChunkChars, and update the m_ChunkLength index as appropriate.
Now we consider the case where there's insufficient space left in the m_ChunkChars buffer to fit valueCount values. In that case, we start by filling up what we can of m_ChunkChars, using a ReadOnlySpan<char> again to copy the values into the buffer. That gives us restLength values remaining.
As we've already filled up this chunk, we need to create a new one, using ExpandByABlock. I described this method in my previous post, in which we create a new StringBuilder, adding an extra chunk to the linked-list.

After running ExpandByABlock(restLength), the current StringBuilder has an empty m_ChunkChars of at least restLength size, so we're free to copy the rest of the data into the m_ChunkChars buffer and return.
There are several other Append() overloads that work with string or Span<char>, but ultimately they delegate down to the methods above for the hard work, so I won't describe them here.
Instead we'll take a look at how some other primitive types are handled, such as int and double.
Appending built-in types
Aside from char (which we looked at in the previous post) there are overloads for most (all?) of the .NET built-in types such as int, double and decimal (some of which are shown below)
public StringBuilder Append(int value) => AppendSpanFormattable(value);
public StringBuilder Append(long value) => AppendSpanFormattable(value);
public StringBuilder Append(float value) => AppendSpanFormattable(value);
public StringBuilder Append(double value) => AppendSpanFormattable(value);
public StringBuilder Append(decimal value) => AppendSpanFormattable(value);
public StringBuilder Append(ushort value) => AppendSpanFormattable(value);
public StringBuilder Append(uint value) => AppendSpanFormattable(value);
All of these methods delegate to the private AppendSpanFormattable<T>(T value) function:
private StringBuilder AppendSpanFormattable<T>(T value) where T : ISpanFormattable
{
if (value.TryFormat(RemainingCurrentChunk, out int charsWritten, format: default, provider: null))
{
m_ChunkLength += charsWritten;
return this;
}
return Append(value.ToString());
}
private Span<char> RemainingCurrentChunk
{
get => new Span<char>(m_ChunkChars, m_ChunkLength, m_ChunkChars.Length - m_ChunkLength);
}
This function has a "fast" case, which uses the TryFromat function defined on ISpanFormattable to try and write the string representation of value in the remaining space available in m_ChunkChars (given by RemainingCurrentChunk).
ISpanFormattable is an interface in the System namespace, which inherits IFormattable and adds a single method:
public interface ISpanFormattable : IFormattable
{
bool TryFormat(Span<char> destination, out int charsWritten, ReadOnlySpan<char> format, IFormatProvider? provider);
}
This function uses Span<T> to efficiently write the "Stringified" version of the value, without creating a string. This is especially useful for StringBuilder as it means the value can be written directly to the internal char[] buffer, without having to create an intermediate string (which would need to be garbage collected).
Unfortunately, this "fast path" only occurs if there is sufficient space for the
stringrepresentation of the value in the current chunk. If thestringrepresentation would cross a chunk boundary, then we have to callToString()on it, and rely on theAppend(string)overload to handle creating a new chunk.
I'm not going to show any of the implementations of TryFormat, as they're generally quite complex (not surprising as they have to handle all the different possible formats and format providers). Instead, I'm going to have a look at an interesting "composite" function: AppendJoin().
Appending lists with separators
string.Join() is a commonly used function for joining lists of values together, inserting a "separator" character between them. For example
var fruit = new [] { "banana", "apple", "orange" };
var combined = string.Join(", ", fruit);
Console.WriteLine(combined); // banana, apple, orange
What if you had a string[], and you wanted to add them all to a StringBuilder with a separator. In .NET Framework, you basically have two options:
- Generate
combinedas above, and add that to theStringBuilder. Thecombinedvariable must be garbage collected later. - Manually iterate through the array, adding each value followed by a separator, and make sure to not add a separator at the end. Doable, but cumbersome as essentially re-implementing
string.Join.
In .NET Core 2.0, AppendJoin was added to StringBuilder. As the name suggests, this essentially combines string.Join() with Append, while ensuring that we don't place more pressure on the garbage collector than necessary.
Just as for string.Join() there are multiple overloads, but they all essentially delegate to the same private function, so I've only shown one below:
public unsafe StringBuilder AppendJoin(string? separator, params string?[] values)
{
separator ??= string.Empty;
fixed (char* pSeparator = separator)
{
return AppendJoinCore(pSeparator, separator.Length, values);
}
}
As for Append(string) at the start of this post, AppendJoin() again uses an unsafe context, creating a fixed pointer for the backing char[] representing the separator values (", " in my example above). It then calls AppendJoinCore<T>(), passing in the pointer, the length of the string, and the values to append. AppendJoinCore<T>() is shown below:
private unsafe StringBuilder AppendJoinCore<T>(char* separator, int separatorLength, T[] values)
{
if (values.Length == 0)
{
return this;
}
if (values[0] != null)
{
Append(values[0]!.ToString());
}
for (int i = 1; i < values.Length; i++)
{
Append(separator, separatorLength);
if (values[i] != null)
{
Append(values[i]!.ToString());
}
}
return this;
}
The AppendJoinCore<T>() method contains pretty much exactly the code you would expect. It loops through each value in values, calling ToString() on the generic argument, and calling Append(string). For the separator, it calls the efficient Append(char*, int) overload we discussed at the start of this post.
Note that ToString() is called on each value in values. For built-in types with specific overloads like int and decimal (that I showed in the previous section), this will result in an additional intermediate string representation. If you need to add these values to your StringBuilder in a hot-path, you might want to consider the hand-rolled approach, so you can take advantage of ISpanFormattable.TryFormat, e.g.
const string prefix = "The winning numbers are: ";
const string separator = ", ";
var lotteryNumbers = new [] { 4, 8, 15, 16, 23, 42 };
// Ensure initial capacity is big enough for final string
var maxSize = prefix.Length + (seperator.Length + 2) * lotteryNumbers.Length;
var sb = new StringBuilder(prefix, capacity: maxSize);
sb.Append(lotteryNumbers[0]); // Uses ISpanFormattable.TryFormat to avoid extra ToString()
for (int i = 1; i < values.Length; i++)
{
Append(", ");
Append(lotteryNumbers[i]); // Uses ISpanFormattable.TryFormat to avoid extra ToString()
}
Console.WriteLine(sb.ToString()); // The winning numbers are: 4, 8, 15, 16, 23, 42
I've covered most of the Append() function overloads now in the first two posts of this series. I skipped over AppendLine(string) as that's trivial:
public StringBuilder AppendLine(string? value)
{
Append(value);
return Append(Environment.NewLine);
}
And I skipped AppendFormat() because it's very non-trivial in terms of length! If you're a completionist, you can see the implementation of AppendFormat on GitHub (all 300+ lines of it). It primarily involves parsing the format string to append arguments at the correct point, rather than any other complex behaviours. Instead, I'll leave the Append*() functions for now. In the next post we'll look at the critical function of a StringBuilder: getting the string out of it!
Summary
In this post I looked at some more of the Append functions in StringBuilder. First we looked atstring, and how we use unsafe contexts and fixed variables to efficiently add the string contents to the StringBuilder. Next we looked at how built in types like int and double are added using the ISpanFormattable interface to avoid intermediate strings. Finally, we looked at AppendJoin that was added in .NET Core 2.0, and is essentially a combination of string.Join and StringBuilder.Append. In the next post we'll look at how StringBuilder.ToString() works.