So far in this series we've covered creating a StringBuilder, appending values to it, and retrieving the final string. In this post, we look at some of the trickier manipulations you can do with StringBuilder: inserting and removing characters.
We'll start by looking at how we can remove characters from a StringBuilder, which is a surprisingly difficult task. Later we move on to inserting characters, which can involve inserting additional chunks, or moving characters around in an existing chunk.
Removing characters from a StringBuilder
The simplest Remove() overload provides a startIndex, and a number of characters to remove. Once you remove the precondition checks, you're left with the following:
public StringBuilder Remove(int startIndex, int length)
{
if (Length == length && startIndex == 0)
{
Length = 0;
return this;
}
if (length > 0)
{
Remove(startIndex, length, out _, out _);
}
return this;
}
This method first checks to see if you're trying to remove all the characters in the StringBuilder. If it is, then we set the property Length to 0. But don't be fooled, this isn't a simple auto-property we're updating. The setter for Length is a complicated method that has to do a lot of work! Rather than dig into it here, we'll assume that we don't want to remove all of the characters in the string, and continue with the remainder of the method. If you're interested, then you can see the implementation here; word of warning, it's involved!
Assuming length>0 then we call the other overload of Remove(). This is a private function which returns the chunk which contains the startIndex after the required number of characters have been removed. We don't need the out variables in this case, so they're discarded. There's quite a lot to this method, so I give the whole thing below, and will reproduce parts of it below as we discuss
private void Remove(int startIndex, int count, out StringBuilder chunk, out int indexInChunk)
{
int endIndex = startIndex + count;
// Find the chunks for the start and end of the block to delete.
chunk = this;
StringBuilder? endChunk = null;
int endIndexInChunk = 0;
while (true)
{
if (endIndex - chunk.m_ChunkOffset >= 0)
{
if (endChunk == null)
{
endChunk = chunk;
endIndexInChunk = endIndex - endChunk.m_ChunkOffset;
}
if (startIndex - chunk.m_ChunkOffset >= 0)
{
indexInChunk = startIndex - chunk.m_ChunkOffset;
break;
}
}
else
{
chunk.m_ChunkOffset -= count;
}
chunk = chunk.m_ChunkPrevious;
}
int copyTargetIndexInChunk = indexInChunk;
int copyCount = endChunk.m_ChunkLength - endIndexInChunk;
if (endChunk != chunk)
{
copyTargetIndexInChunk = 0;
// Remove the characters after `startIndex` to the end of the chunk.
chunk.m_ChunkLength = indexInChunk;
// Remove the characters in chunks between the start and the end chunk.
endChunk.m_ChunkPrevious = chunk;
endChunk.m_ChunkOffset = chunk.m_ChunkOffset + chunk.m_ChunkLength;
// If the start is 0, then we can throw away the whole start chunk.
if (indexInChunk == 0)
{
endChunk.m_ChunkPrevious = chunk.m_ChunkPrevious;
chunk = endChunk;
}
}
endChunk.m_ChunkLength -= (endIndexInChunk - copyTargetIndexInChunk);
// SafeCritical: We ensure that `endIndexInChunk + copyCount` is within range of `m_ChunkChars`, and
// also ensure that `copyTargetIndexInChunk + copyCount` is within the chunk.
// Remove any characters in the end chunk, by sliding the characters down.
if (copyTargetIndexInChunk != endIndexInChunk) // Sometimes no move is necessary
{
new ReadOnlySpan<char>(endChunk.m_ChunkChars, endIndexInChunk, copyCount).CopyTo(endChunk.m_ChunkChars.AsSpan(copyTargetIndexInChunk));
}
}
The first part of the method is about working out which of the StringBuilder chunks in the list are affected by the Remove().
private void Remove(int startIndex, int count, out StringBuilder chunk, out int indexInChunk)
{
int endIndex = startIndex + count;
// Find the chunks for the start and end of the block to delete.
chunk = this;
StringBuilder? endChunk = null;
int endIndexInChunk = 0;
while (true)
{
if (endIndex - chunk.m_ChunkOffset >= 0)
{
if (endChunk == null)
{
// This chunk contains the end of removed characters
endChunk = chunk;
endIndexInChunk = endIndex - endChunk.m_ChunkOffset;
}
if (startIndex - chunk.m_ChunkOffset >= 0)
{
// chunk contains the startIndex
indexInChunk = startIndex - chunk.m_ChunkOffset;
break;
}
}
else
{
chunk.m_ChunkOffset -= count;
}
chunk = chunk.m_ChunkPrevious;
}
// ...
}
We start by calculating the endIndex we're looking for, and set the first chunk to this.
Remember, the
StringBuilderpointed to bythiscontains the finalchars in thestring, while referenced chunks point tochars nearer the start of the string, as shown below.

m_ChunkOffset is the number of characters in previous chunks, so we first check if the endIndex is greater than m_ChunkOffset. If it isn't, then we know that the chars to remove are in "earlier" chunks, so we decrement this chunk's m_ChunkOffset, and move onto the next chunk.
If the current chunk does incorporate the endIndex then we set endChunk if it's not already set. We then check to see if this chunk also includes the startIndex. If it does, we set indexInChunk and exit the while loop. If it doesn't, we will keep moving along chunks until we find the one that does.
Once this block has finished, the following values have been set:
endChunk—contains the last character that will be removedendIndexInChunk—the index of the lastm_ChunkCharsentry inendChunkthat will be removedchunk—contains the first character that will be removedindexInChunk—the index of the firstm_ChunkCharsentry inchunkthat will be removed

Let's move on to the second part of the method.
private void Remove(int startIndex, int count, out StringBuilder chunk, out int indexInChunk)
{
// set in the previous block
StringBuilder? endChunk = ;
int endIndexInChunk =;
chunk = ;
indexInChunk = ;
// ...
int copyTargetIndexInChunk = indexInChunk;
int copyCount = endChunk.m_ChunkLength - endIndexInChunk;
if (endChunk != chunk)
{
copyTargetIndexInChunk = 0;
// Remove the characters after `startIndex` to the end of the chunk.
chunk.m_ChunkLength = indexInChunk;
// Remove the characters in chunks between the start and the end chunk.
endChunk.m_ChunkPrevious = chunk;
endChunk.m_ChunkOffset = chunk.m_ChunkOffset + chunk.m_ChunkLength;
// If the start is 0, then we can throw away the whole start chunk.
if (indexInChunk == 0)
{
endChunk.m_ChunkPrevious = chunk.m_ChunkPrevious;
chunk = endChunk;
}
}
// ...
}
In this second section, we look at the chunk that contains the start index, indexInChunk, as long as it's different to the end index. If that's the case we "delete" everything after the start index, by simply setting the m_ChunkLength appropriately. As this field says how many characters are used, we don't actually have to erase any of the buffer.
Next, we remove any chunks between the start chunk and endChunk by setting the endChunk.m_ChunkPrevious to point directly to chunk. Any chunks that were previously between chunk and endChunk will now be unreferenced. We then update endChunk.mChunkOffset as appropriate. As a final step in the conditional, if indexInChunk==0, then we can remove chunk from the linked list entirely!
We're on to the final part of the method now. This part of the method is well commented, so I'll leave it to speak for itself.
private void Remove(int startIndex, int count, out StringBuilder chunk, out int indexInChunk)
{
// ...
int copyTargetIndexInChunk = indexInChunk; // 0 if endChunk!=chunk
// Set the final number of characters endchunk will contain
endChunk.m_ChunkLength -= (endIndexInChunk - copyTargetIndexInChunk);
// SafeCritical: We ensure that `endIndexInChunk + copyCount` is within range of `m_ChunkChars`, and
// also ensure that `copyTargetIndexInChunk + copyCount` is within the chunk.
// Remove any characters in the end chunk, by sliding the characters down.
if (copyTargetIndexInChunk != endIndexInChunk) // Sometimes no move is necessary
{
new ReadOnlySpan<char>(endChunk.m_ChunkChars, endIndexInChunk, copyCount).CopyTo(endChunk.m_ChunkChars.AsSpan(copyTargetIndexInChunk));
}
}
Phew, that was quite a complicated one, with lots of indexes moving around. The final result aims to copy as few bytes around as possible - in general it's only the end chunk that will need to copy bytes, and even then we do our best to avoid copying more than necessary.
We've now successfully removed some characters from a StringBuilder, but what if we want to do the reverse? In the next section, I look at the Insert(string) method.
Inserting a string
There are a whole range of Insert() methods on StringBuilder, much as there is for Append(). However, it's worth being aware that while the Append() functions optimise appending built-in types using ISpanFormattable (as I discussed in a previous post), the Insert() methods aren't optimised. They currently call ToString() on the provided value, resulting in an additional allocation, for example:
public StringBuilder Insert(int index, int value) => Insert(index, value.ToString(), 1);
In this section I'll look at Insert(string) and its dependencies. The first method is similar to the Append equivalent, in that it enters an unsafe context and obtains a fixed pointer to the first character in the string to add. It then passes this into a private, unsafe overload of Insert.
public StringBuilder Insert(int index, string? value)
{
if (value != null)
{
unsafe
{
fixed (char* sourcePtr = value)
{
Insert(index, sourcePtr, value.Length);
}
}
}
return this;
}
This private overload calls two methods: MakeRoom, which creates an empty "gap" at the logical index; and ReplaceInPlaceAtChunk which fills in the gap with the original string value.
private unsafe void Insert(int index, char* value, int valueCount)
{
if (valueCount > 0)
{
MakeRoom(index, valueCount, out StringBuilder chunk, out int indexInChunk, false);
ReplaceInPlaceAtChunk(ref chunk!, ref indexInChunk, value, valueCount);
}
}
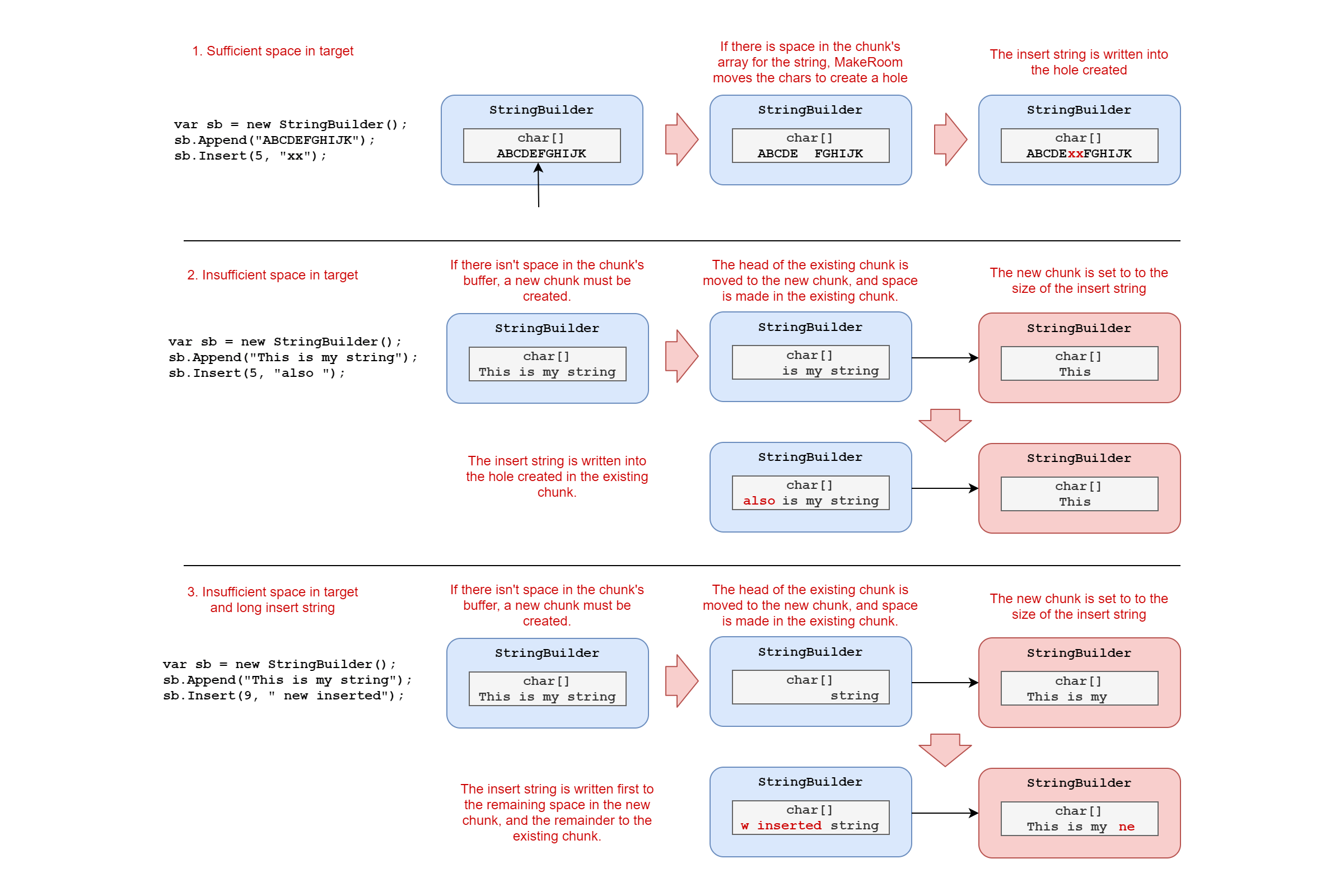
MakeRoom does one of three things:
- If there is sufficient space in an existing chunk's buffer array (because the buffer isn't full yet), then it shifts the characters in the buffer along and makes space that way.
- If there isn't space for that, it inserts a new chunk, copies across the characters from the head of the existing chunk into the new one, and uses that to make space in the existing chunk.
- If there isn't room for that, it still adds a new chunk, and partially fills the new chunk before moving on to the existing one.

The MakeRoom function is, again, pretty well commented, so I've just enhanced the code below with some extra comments.
private void MakeRoom(int index, int count, out StringBuilder chunk, out int indexInChunk, bool doNotMoveFollowingChars)
{
chunk = this;
// Loop through until we find the chunk that contains index
while (chunk.m_ChunkOffset > index)
{
// For later chunks, add the count to m_ChunkOffset, as we know the total size
// wil increase by this number of chars
chunk.m_ChunkOffset += count;
chunk = chunk.m_ChunkPrevious;
}
// We've found the chunk that contains index, so calculate the required location in m_ChunkChars
indexInChunk = index - chunk.m_ChunkOffset;
// Cool, we have some space in this block, and we don't have to copy much to get at it, so go ahead and use it.
// This typically happens when someone repeatedly inserts small strings at a spot (usually the absolute front) of the buffer.
if (!doNotMoveFollowingChars && chunk.m_ChunkLength <= DefaultCapacity * 2 && chunk.m_ChunkChars.Length - chunk.m_ChunkLength >= count)
{
// Starting at the end of the buffer that contains data
// Create a "hole" by moving the characters to the right
for (int i = chunk.m_ChunkLength; i > indexInChunk;)
{
--i;
chunk.m_ChunkChars[i + count] = chunk.m_ChunkChars[i];
}
chunk.m_ChunkLength += count;
// All done, m_ChunkChars contains a count size "hole" at index
return;
}
// There wasn't space in the chunk's m_ChunkChars, so we need to add a new chunk
// Allocate space for the new chunk, which will go before the current one.
StringBuilder newChunk = new StringBuilder(Math.Max(count, DefaultCapacity), chunk.m_MaxCapacity, chunk.m_ChunkPrevious);
newChunk.m_ChunkLength = count;
// Copy the head of the current buffer to the new buffer.
int copyCount1 = Math.Min(count, indexInChunk);
// if indexInChunk (or count) is 0, then we don't need to do any copying, the chunk is enough
if (copyCount1 > 0)
{
// copy the start of the chunk into the newChunk
new ReadOnlySpan<char>(chunk.m_ChunkChars, 0, copyCount1)
.CopyTo(newChunk.m_ChunkChars);
// Slide characters over in the current buffer to make room
// as long as there _is_ room
int copyCount2 = indexInChunk - copyCount1;
if (copyCount2 >= 0)
{
// slide the characters from copyCount1..copyCount2 to the start of the array
new ReadOnlySpan<char>(chunk.m_ChunkChars, copyCount1, copyCount2)
.CopyTo(chunk.m_ChunkChars);
// we're now pointing to the start of the hole
indexInChunk = copyCount2;
}
}
// Wire in the new chunk.
chunk.m_ChunkPrevious = newChunk;
chunk.m_ChunkOffset += count;
if (copyCount1 < count)
{
// if there was insufficient space in the existing chunk, we need to point to the new chunk instead
chunk = newChunk;
indexInChunk = copyCount1;
}
}
MakeRoom is where the bulk of the complexity is in Replace(), but we still need to copy the characters in. Thanks to the design of MakeRoom we already have a reference to the chunk and the index in that chunk where we need to write the value. The only complexity is that we don't necessarily have space in a single chunk, so we may need to write some characters to the next chunk.
private unsafe void ReplaceInPlaceAtChunk(ref StringBuilder? chunk, ref int indexInChunk, char* value, int count)
{
if (count != 0)
{
while (true)
{
// The space available in the chunk
int lengthInChunk = chunk.m_ChunkLength - indexInChunk;
int lengthToCopy = Math.Min(lengthInChunk, count);
// Write what we can in this chunk
new ReadOnlySpan<char>(value, lengthToCopy)
.CopyTo(chunk.m_ChunkChars.AsSpan(indexInChunk));
// Advance the index.
indexInChunk += lengthToCopy;
// If we've reached the end of this chunk, we need to fetch a new one
if (indexInChunk >= chunk.m_ChunkLength)
{
chunk = Next(chunk);
indexInChunk = 0;
}
// decrease the number of characters left
count -= lengthToCopy;
// check if we're done
if (count == 0)
{
break;
}
// Move the char* pointer to point to the next values to copy
value += lengthToCopy;
}
}
}
ReplaceInPlaceAtChunk uses the Next(chunk) method to get the next chunk in the linked list towards the head. This is harder than it seems, as StringBuilder only maintains a reference to the previous chunk i.e. it's a singly linked list. If you remember back to the first post in this series, the head of the list contains the final chars of the string, and refers to earlier chunks. We want to go from a later chunk, and move to the left on the following diagram.
To get the Next chunk we have to start at the head and walk backwards!
private StringBuilder? Next(StringBuilder chunk) =>
chunk == this ? null : FindChunkForIndex(chunk.m_ChunkOffset + chunk.m_ChunkLength);
private StringBuilder FindChunkForIndex(int index)
{
StringBuilder result = this;
while (result.m_ChunkOffset > index)
{
result = result.m_ChunkPrevious;
}
return result;
}
FindChunkForIndex starts from the head of the linked list (this), and walks backwards until it finds a chunk with an m_ChunkOffset greater than the combined offset and length of the original chunk. As soon as it finds this chunk, it returns it (and ReplaceInPlaceAtChunk can fill it in).
That brings us to the end of this post, and to the end of my in-depth look at StringBuilder. There are still more methods and properties I could look into, but I think I've covered a good selection already, and demonstrated some interesting logic and challenges involved in working with the data structure. In the next post I look at a different class entirely, StringBuilderCache.
Summary
In this post I described how the Remove() and Insert() methods of StringBuilder() work. These methods often involve manipulating StringBuilder chunks in the middle of the linked list, which presents some interesting challenges. The Remove() method has to ensure