In the previous posts in this series, I took a first look at the internal design of StringBuilder class as a linked list, and then looked at the source code behind the constructors and Append methods. In this post I look at (arguably) the most important method on StingBuilder, ToString(), and show how the final string is created from multiple chunks. I also looks at the overload ToString(startIndex, count), and show how recent implementations differ from that used in .NET Framework.
Terminology recap
In the first post in this series I provided an explanation of the important fields and properties in StringBuilder. Rather than make you flick back there, I've provided a summary of the important ones for this post below:
char[] m_ChunkChars—The internal buffer of characters for the chunk, representing part of the overallstring.StringBuilder? m_ChunkPrevious—A reference to the previous chunk. This will benulluntil a new chunk is added.int m_ChunkLength—The number of characters that have been added to this chunk's buffer. Will always be between0andm_ChunkChars.Length.int m_ChunkOffset—The total number of characters in previous chunks. Will be0until a new chunk is added.Length—The number of characters added to the builder. Given bym_ChunkLength + m_ChunkOffset. Note that this will be less than or equal toCapacity, and is the length of thestringyou will get when callingToString().
Overriding the default ToString() method
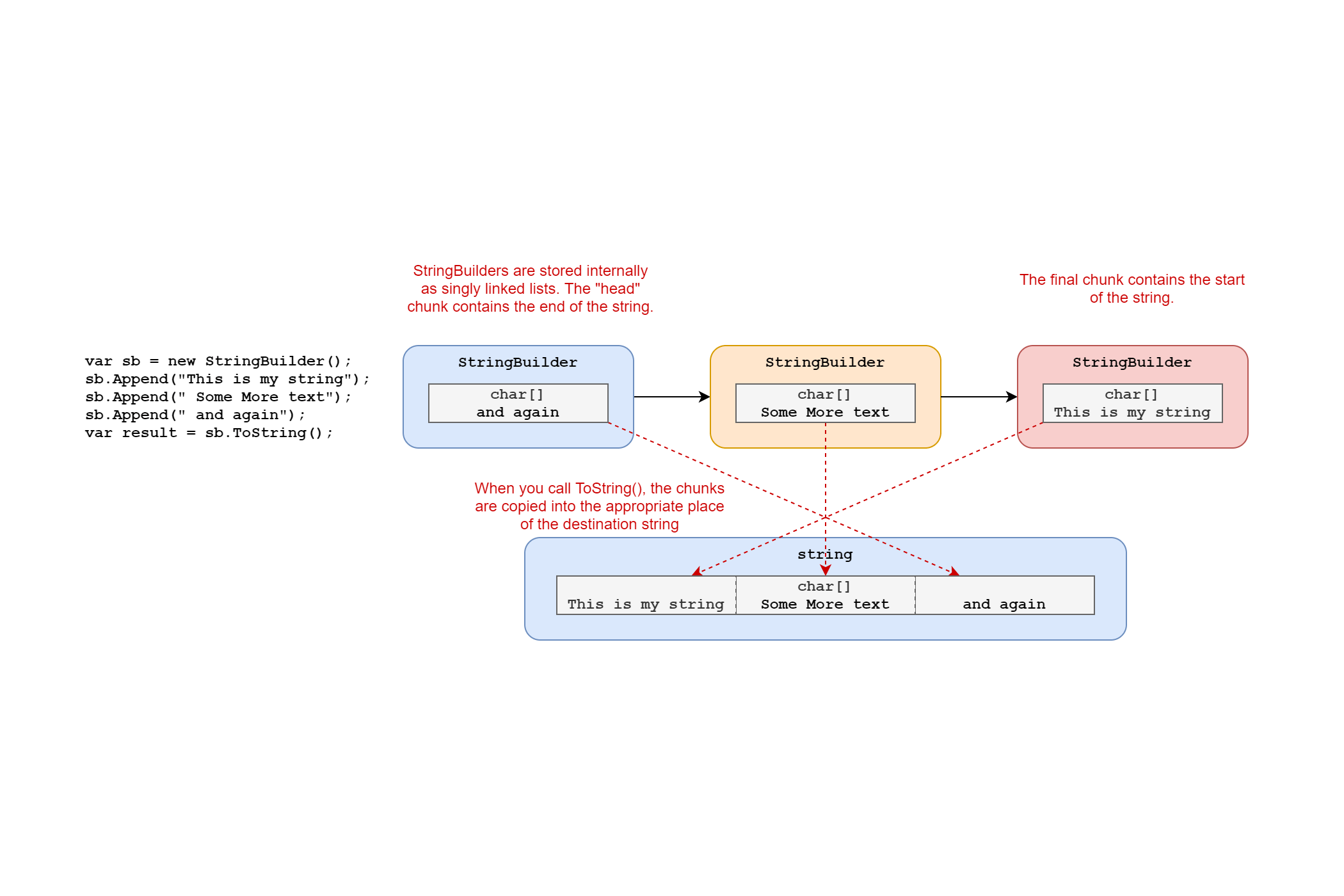
Once you've added all your partial strings to StringBuilder, you call ToString() to get the final string out. In simple cases, that may simply involve converting a char[] buffer into a string. But remember that under-the-hood, StringBuilder is implemented as a singly linked list, so we may have multiple chunks that need to be combined. The implementation of ToString() is shown below, I'll talk through it subsequently.
public override string ToString()
{
if (Length == 0)
{
return string.Empty;
}
string result = string.FastAllocateString(Length);
StringBuilder? chunk = this;
do
{
if (chunk.m_ChunkLength > 0)
{
// Copy these into local variables so that they are stable even in the presence of race conditions
char[] sourceArray = chunk.m_ChunkChars;
int chunkOffset = chunk.m_ChunkOffset;
int chunkLength = chunk.m_ChunkLength;
// Check that we will not overrun our boundaries.
if ((uint)(chunkLength + chunkOffset) > (uint)result.Length || (uint)chunkLength > (uint)sourceArray.Length)
{
throw new ArgumentOutOfRangeException(nameof(chunkLength), SR.ArgumentOutOfRange_Index);
}
Buffer.Memmove(
ref Unsafe.Add(ref result.GetRawStringData(), chunkOffset),
ref MemoryMarshal.GetArrayDataReference(sourceArray),
(nuint)chunkLength);
}
chunk = chunk.m_ChunkPrevious;
}
while (chunk != null);
return result;
}
We start by doing a simple check for the condition where Length=0. That means there are no characters stored in any chunks, so we can return String.Empty. If that's not the case, and we do have some characters, then we call string.FastAllocateString().
FastAllocateString() is an internal method which is implemented in C++ by the CLR, indicated by the extern keyword on its definition:
public partial class String
{
[MethodImpl(MethodImplOptions.InternalCall)]
internal static extern string FastAllocateString(int length);
}
Allocating memory for a string is such a common scenario that this method contains hand-written assembly code. If you'd like to go deeper into this, I suggest looking at Matt Warren's excellent post on the special relationship between strings and the CLR.
After the call to FastAllocateString we have a reference to a string, but the "data" for that string is uninitialized. For performance reasons, we later mutate the underlying data to have the values we need.
strings are meant to be immutable, so mutating them like this is very unusual and (generally) not possible outside of the core libraries, as the required methods to do so are not exposed. It is used in the core libraries in performance-sensitive areas, where the benefits are worthwhile, and the situation is simple enough to make the risk of errors sufficiently small. If you need something similar, I suggest looking at thestring.Create()method. Steve Gordon has a great post on this API here.
After allocating the memory for the string, we start walking the linked list of StringBuilder chunks, starting with the current chunk. If you think back to the first post in this series, you may recall that the reference to the StringBuilder held by the consumer is to the head of the list, but that this contains the final block of characters for the string.

That means we need to write the characters at the end of the string first. When we move to the next StringBuilder chunk, we will fill in the next block of characters from the end, and so on, until we get to the final chunk, which contains the characters for the start of the string. Bearing that in mind, let's go back to the code.
Assuming the first chunk contains some data, then we first copy our fields to local variables to avoid any issues with race conditions, and then confirm that we haven't inadvertently overrun our boundaries. This shouldn't happen in normal operation, but as we're going to be working with raw memory, it pays to be sure!
The heavy lifting of the loop is done by Buffer.Memmove(), but there are a lot of additional method calls involved here too:
Buffer.Memmove(
ref Unsafe.Add(ref result.GetRawStringData(), chunkOffset),
ref MemoryMarshal.GetArrayDataReference(sourceArray),
(nuint)chunkLength);
These are all quite interesting methods but for space reasons, I'm not going to go into detail about them. Instead, here's a summary of what they do:
ref string.GetRawStringData()—Get a reference to the firstcharof the rawstring's memory, and store it as a ref local variable.ref Unsafe.Add<T>(ref T, count)—Increments a memory address bycountelements.MemoryMarshal.GetArrayDataReference<T>(T[])—Returns a ref local pointing to the first element in the arrayBuffer.Memmove(dest, src, count)—Aninternalmethod that efficiently copiescountelements of the memory fromsrctodest.
As you might anticipate, the upshot of this is to copy the memory from the sourceArray (which contains the current chunk's m_ChunkChars buffer) to the appropriate place in the destination string's memory. The use of ref returns and ref locals avoids the use of pointer arithmetic, which in turn avoids the need to "pin" references in memory. Avoiding unsafe code this way can actually have performance benefits, as it means code can still be inlined.
Given that fact, I'm not entirely sure why
unsafecode is used by theAppend(string)methods I discussed in my previous post instead of ref returns etc. I'm sure there's a performance/ergonomics reason, but I don't what it is off the top of my head!
Once the chunk's data is copied, the chunk reference is set to the next StringBuilder in the linked list, and the process is repeated until all chunks are completed, and the final result is returned.
This ToString() implementation overrides the default ToString() implementation, but StringBuilder includes another overload in which you provide a startIndex and a length. In the next section we'll look at that overload, and its dependencies.
Materialising part of the string with ToString(startIndex, length)
In some situations, you may only need a portion of the characters added to a StringBuilder. Luckily, there's a ToString() overload for that, shown below (I've removed the expected precondition checks for out-of-range arguments etc):
public string ToString(int startIndex, int length)
{
int currentLength = this.Length;
string result = string.FastAllocateString(length);
unsafe
{
fixed (char* destinationPtr = result)
{
this.CopyTo(startIndex, new Span<char>(destinationPtr, length), length);
return result;
}
}
}
This overload again uses FastAllocateString to efficiently allocate memory for a string, but in this case it uses an unsafe context and fixed pointer to wrap a Span<char> around the uninitialized string memory. This is then passed to the StringBuilder.CopyTo() function to do the actual copying.
The CopyTo function is a public method that can be used to copy the contents of the StringBuilder to any Span<char> array. It works in a similar way to the ToString() method, but otherwise uses "safe" copy methods, with no need for unsafe or ref returns.
As already discussed, the first StringBuilder chunk in the linked list holds the characters for the last section of the string. A large part of the method body is around counting backwards in the source (StringBuilder) arrays, while counting forwards in the destination Span<T>. This is all a bit tedious, so I'm not going to go into more detail. Instead I've annotated the code with a few comments to make it clearer what's going on:
public void CopyTo(int sourceIndex, Span<char> destination, int count)
{
StringBuilder? chunk = this;
// The final index to copy, if all the StringBuilder chunks are concatenated
int sourceEndIndex = sourceIndex + count;
int curDestIndex = count;
while (count > 0)
{
// The last index to copy across all chunks
int chunkEndIndex = sourceEndIndex - chunk.m_ChunkOffset;
if (chunkEndIndex >= 0)
{
// Find the last index to copy in _this_ chunk
chunkEndIndex = Math.Min(chunkEndIndex, chunk.m_ChunkLength);
// Calculate the start index for this chunk
int chunkCount = count;
int chunkStartIndex = chunkEndIndex - count;
// If this is -ve (likely if we need to copy across multiple chunks)
if (chunkStartIndex < 0)
{
// set chunkCount to the number of chars to copy in this chunk
chunkCount += chunkStartIndex;
// from the start of the chunk
chunkStartIndex = 0;
}
// We're copying _backwards_ into the destination, so set the destination as approrpriate
curDestIndex -= chunkCount;
// Decrement the number of remaining chars to copy
count -= chunkCount;
// Copy chunkCount chars from m_ChunkChars to the destination
new ReadOnlySpan<char>(chunk.m_ChunkChars, chunkStartIndex, chunkCount).CopyTo(destination.Slice(curDestIndex));
}
// Set the chunk to the next StringBuilder in the linked list
chunk = chunk.m_ChunkPrevious;
}
}
Although there's a lot manipulating indexes around in this method, the actual mechanics of efficiently copying data around is made a lot easier by the use of Span<T>. In .NET Framework (which doesn't have a native Span<T>) the implementation falls back to an unsafe context and direct pointer manipulation. As you'd expect, most of the method mirrors the .NET Core version, the main difference is where .NET Core uses Span<T>:
// Copy chunkCount chars from m_ChunkChars to the destination
new ReadOnlySpan<char>(chunk.m_ChunkChars, chunkStartIndex, chunkCount)
.CopyTo(destination.Slice(curDestIndex));
the .NET Framework implementation uses the equivalent of:
// work off of local variables so that they are stable even in the presence of ----s (hackers might do this)
char[] sourceArray = chunk.m_ChunkChars;
// Check that we will not overrun our boundaries.
if ((uint)(chunkCount + curDestIndex) <= length && (uint)(chunkCount + chunkStartIndex) <= (uint)sourceArray.Length)
{
fixed (char* sourcePtr = &sourceArray[chunkStartIndex])
{
string.wstrcpy(destinationPtr + curDestIndex, sourcePtr, chunkCount);
}
}
else
{
throw new ArgumentOutOfRangeException("chunkCount", Environment.GetResourceString("ArgumentOutOfRange_Index"));
}
This relies on pinning a reference to the StringBuilder's buffer, and using string.wstrcpy (which in turn delegates to the internal Buffer.Memcpy()). All a bit more involved than using Span<T> which handles the concerns of safe memory access for you.
So far in this series we've covered creating a StringBuilder, appending values to it, and retrieving the final string. In the next post, we look at some of the trickier manipulations you can do with StringBuilder: inserting and removing characters.
Summary
In this post I looked at the ToString() methods of StringBuilder. While exploring these methods we discovered a number of low-level and internal methods such as string.FastAllocateString(), string.GetRawStringData(), and Buffer.Memmove(). These allow direct manipulation of memory, ensuring high performance. Due to the danger of these methods if used incorrectly, they're not exposed publicly, so you can't use them in your own apps. However, you can achieve many similar things using those methods which are exposed, such as Unsafe.Add<T>() and MemoryMarshal.GetArrayDataReference<T>(T[]), or preferably using the simpler Span<T> APIs.