This post is the first in a series on deploying ASP.NET Core applications to Kubernetes. In this series I'll cover a variety of topics and things I've learned in deploying applications to Kubernetes. I'm not an expert on Kubernetes by any means, so I'm not going to go deep into a lot of the technical aspects, or describe setting up a Kubernetes cluster. Instead I'm going to focus on the app-developer's side, taking an application and deploying it to an existing cluster.
Important note: I started writing this blog series about a year ago, but it's been delayed for various reasons (ahem, procrastination). Since then Project Tye has arisen as a promising new way to deploy ASP.NET Core apps to Kubernetes. I won't touch on Project Tye in this series, though I'm sure I'll blog about it soon!
This series does not focus on using Docker with ASP.NET Core in general. Steve Gordon has an excellent blog series on Docker for .NET developers, as well as multiple talks and videos on the subject. I also have many other posts on my blog about using Docker with ASP.NET Core. Scott Hanselman has also a recent 101 introduction to containers. Note that although production-level support for Windows has been around for a while I'm only going to be considering Linux hosts for this series.
Another important point is that I don't consider myself a Kubernetes expert by any means! The approaches I describe in this series are very much taken from my own experience of deploying ASP.NET Core applications to a Kubernetes cluster. If there's anything that you don't agree with or looks incorrect, please do let me know in the comments! 🙂
In this post I describe some of the fundamental concepts that you'll need to be familiar with to deploy ASP.NET Core applications to Kubernetes.
What is Kubernetes and do I need it?
Kubernetes is an open-source platform for orchestrating containers (typically Docker containers). It manages the lifecycle and networking of containers that are scheduled to run, so you don't have to worry if your app crashes or becomes unresponsive - Kubernetes will automatically tear it down and start a new container.
The question of whether you need to use Kubernetes is an interesting one. There definitely seems to be a push towards it from all angles these days, but you have to realise it adds a lot of complexity. If you're building a monolithic app, Kubernetes is unlikely to bring you value. Even if you're heading towards smaller services, it's not necessary to immediately jump on the band wagon. The question is: is service orchestration (the lifetime management and connection between multiple containers) currently a problem for you, or is it likely to be soon? If the answer is yes, then Kubernetes might be a good call. If not, then it probably isn't.
How much do I need to learn?
Having a deep knowledge of the concepts and features underlying Kubernetes will no doubt help you diagnose any deployment or production issues faster. But Kubernetes is a large, fast moving platform, so it can be very overwhelming! One of the key strengths of Kubernetes - its flexibility - is also one of the things that I think makes it hard to grasp.
For example, the networking stack is pluggable, so you can swap in and out network policy managers. Personally I find networking to be a nightmare to understand at the best of times, so having it vary cluster-to-cluster makes it a minefield!
The good news is that if you're only interested in deploying your applications, then the cognitive overhead drops dramatically. That's the focus of this series, so I'm not going to worry about kubelets, or the kube-apiserver, and other such things. If you already know about them or want to read up, great, but they're not necessary for this series.
Also, it might well be worth looking at the platform offerings for Kubernetes from Azure, AWS, or Google. These provide managed installations of Kubernetes, so if you are having to dive deeper into Kubernetes, you might find they simplify many things, especially getting up and running.
The basic Kubernetes components for developers
Instead of describing the multitude of pieces that make up a Kubernetes cluster, I'm going to describe just five concepts:
I'm not going to be deeply technical, I'm just trying to lay the framework for later posts 🙂
Nodes
Nodes in a Kubernetes cluster are Virtual Machines or physical hardware. It's where Kubernetes actually runs your containers. There are typically 2 types of Node
- The master node, which contains all the "control plane" services required to run a cluster. Typically the master node only handles this management access, and doesn't run any of your containerised app workloads.
- Other nodes, which are used to run your applications. A single node can run many containers, depending on the resource constraints (memory, CPU etc) of the node.

The reality is less clearly segregated, but if you're not managing the cluster, it's probably not something you need to worry about. Note that if you're running a Kubernetes cluster locally for development purposes it's common to have a single Node (your machine or a VM) which is a master node that has been "tainted" to also run containers.
As it looks pretty cool, I have to point out there's also an Azure service for creating "virtual nodes" which allows you to spin up Container Instances dynamically as load increases. Worth checking out if you're using Azure's managed Kubernetes service. AWS has a similar service, Fargate, which should make scaling clusters easier.
tl;dr; Nodes are VMs that run your app. The more Nodes you have, the more containers you can run and (potentially) more fault tolerant you are if one Node goes down.
Pods
To run your application in Kubernetes, you package it into a container (typically a Docker container) and ask Kubernetes to run it. A pod is the smallest unit that you can ask Kubernetes to run. It contains one or more containers. When a pod is deployed or killed, all of the containers inside it are started or killed together.
Side note: the name "pod" comes from the collective noun for a group of whales, so think of a pod as a collection of your Docker (whale) containers.
When I was first learning Kubernetes, I was a bit confused about the pod concept. The whole point of splitting things into smaller services is to be able to deploy them independently right?
I think part of my confusion was due to some early descriptions I heard. For example: "if you have an app that depends on a database, you might deploy the app container and database container in the same pod, so they're created and destroyed together".
I don't want to say that's wrong, but it's an example of something I would specifically not do! It's far more common to have pods that contain a single container - for example a "payment API" or the "orders API". Each of those APIs may have different scaling needs, different deployment and iteration rates, different SLAs, and so on, so it makes sense for them to be in separate pods. Similarly, a database container would be deployed in its own separate pod, as it generally will have a different lifecycle to your app/services.
What is relatively common is having "supporting" containers deployed alongside the "main" container in a pod, using the sidecar pattern. These sidecar containers handle cross-cutting concerns for the main application. For example, they might act like a proxy and handle authentication for the main app, handle service discovery and service-mesh behaviours, or act as a sink for application performance monitoring. This is the pattern that the new Dapr runtime relies on.

The ability to deploy "pods" rather than individual containers like this makes composability and handling cross-cutting concerns easier. But the chances are that when you start, your pods will just have a single container: the app/API/service that you're deploying. So in most cases, when you see/hear "pod" you can think "container".
tl;dr; Pods are a collection of containers that Kubernetes schedules as a single unit. Initially your pods will likely contain a single container, one for each API or app you're deploying.
Deployments
I've said that Kubernetes is an orchestrator, but what does that really mean? You can run Docker containers without an orchestrator using docker run payment-api, so what does Kubernetes add?
Orchestration in my mind is primarily about two things:
- Managing the lifetime of containers
- Managing the communication between containers
Deployments in Kubernetes are related to the first of those points, managing the lifetime of containers. You can think of a deployment as a set of declarative statements about how to deploy a pod, and how Kubernetes should manage it. For example, a deployment might say:
- The pod contains one instance of the
payment-api:abc123Docker image - Run 3 separate instances of the pod (the number of replicas)
- Ensure the
payment-api:abc123container has 200Mb of memory available to it, but limit it to using a max of 400Mb - When deploying a new version of a pod use a rolling update strategy
Kubernetes will do its best to honour the rules you define in a deployment. If your app crashes, Kubernetes will remove the pod and schedule a new one in order to keep the number of replicas you've specified. If your pod needs more memory, it may start running it on a different node where there are fewer containers running, or it might kill it and redeploy it. The key is that it moves towards the desired state specified in the deployment.
When you deploy a new version of your app (e.g. Docker image payment-api:def567) you create a new deployment in the cluster, replacing the previous deployment. Kubernetes will work on moving from the previous state to the new desired state, killing and starting pods as necessary.
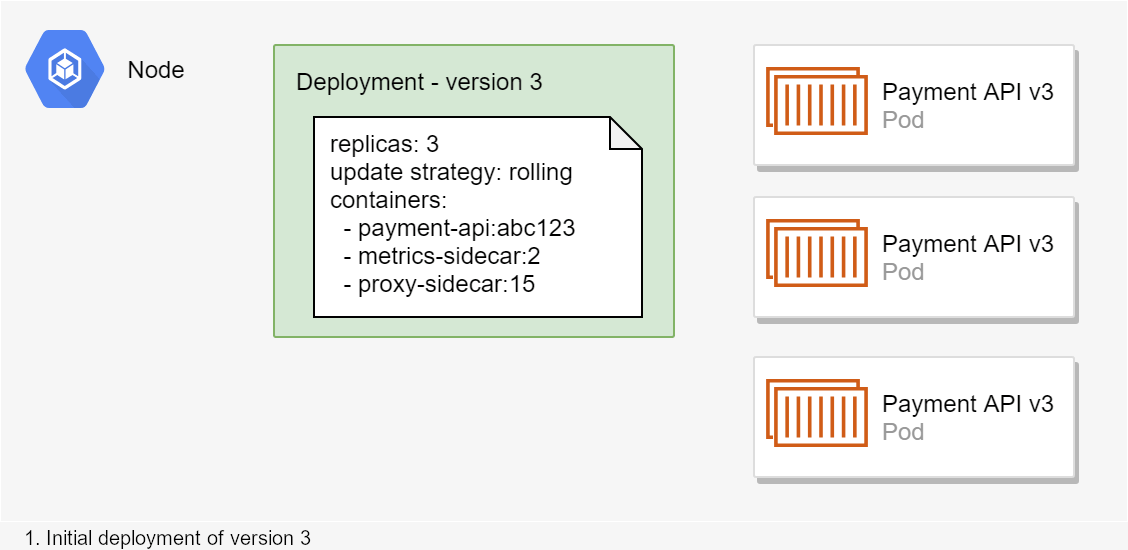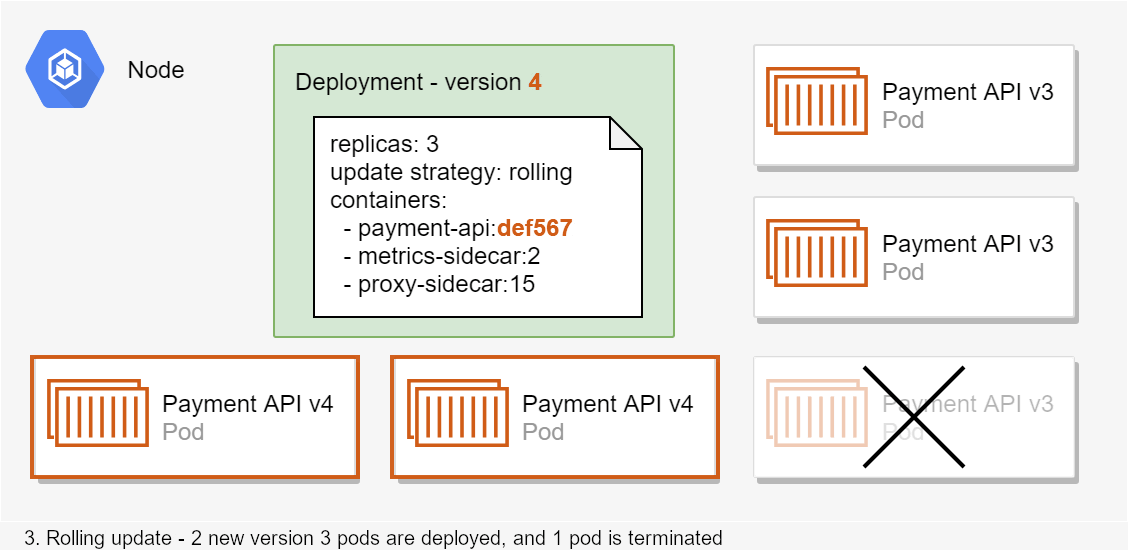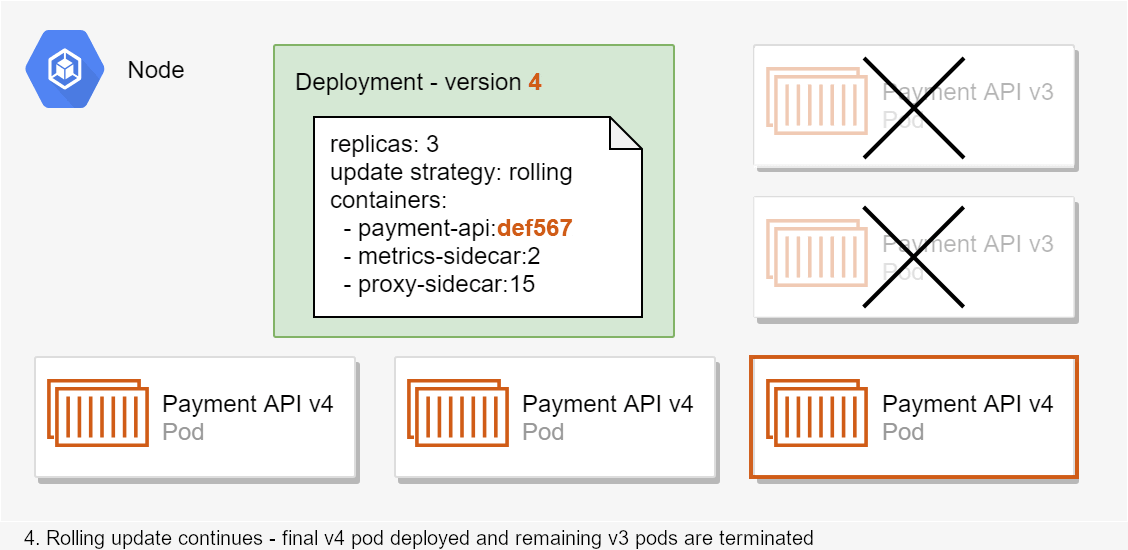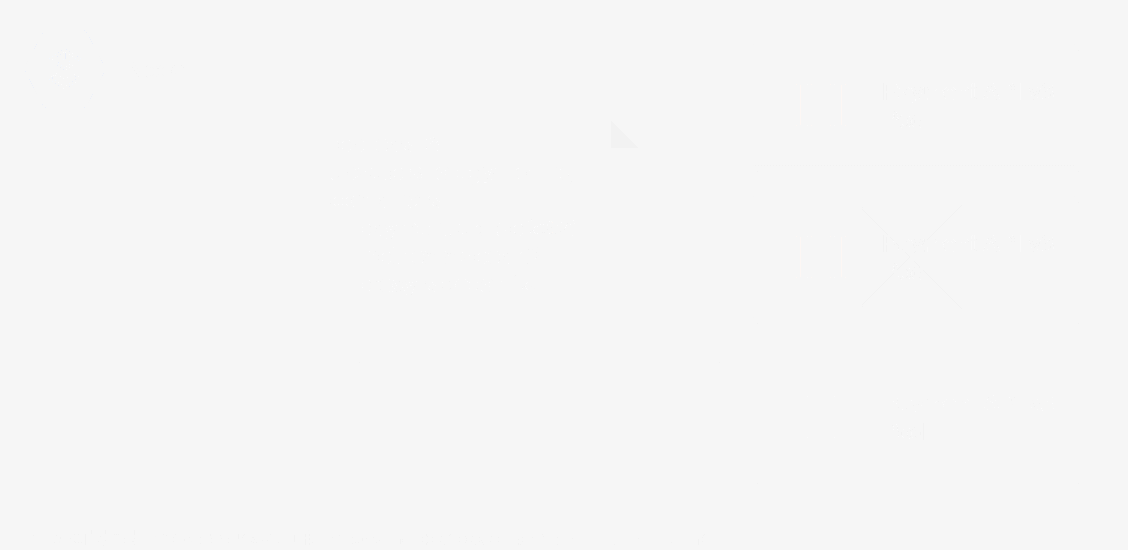
In the animated example shown above, the cluster initially has three replicas of the payment-api:abc123 pod running. Then a new deployment is applied (version 4) that requires 3 instances of payment-api:def567 (a different docker image). Based on the "rolling update" strategy defined by the deployment, Kubernetes decides to take the following action:
- Start two new instances of the
payment-api:def567pod and stop one instance of thepayment-api:abc123pod - Wait for the two new instances to start handling requests
- Once the new pods are working, stop the remaining
payment-api:abc123pods and start the last requiredpayment-api:def567pod
This example is simplified (I've only considered one node for example), but it describes the general idea. The key takeaway is that deployments define the desired state, which Kubernetes aims to maintain throughout the lifetime of the deployment. You'll see the technical side of creating deployments in the next post in the series in which we look at manifests.
tl;dr; Deployments are used to define how Pods are deployed, which Docker images they should use, how many replicas should be running, and so on. They represent the desired state for the cluster, which Kubernetes works to maintain.
Services
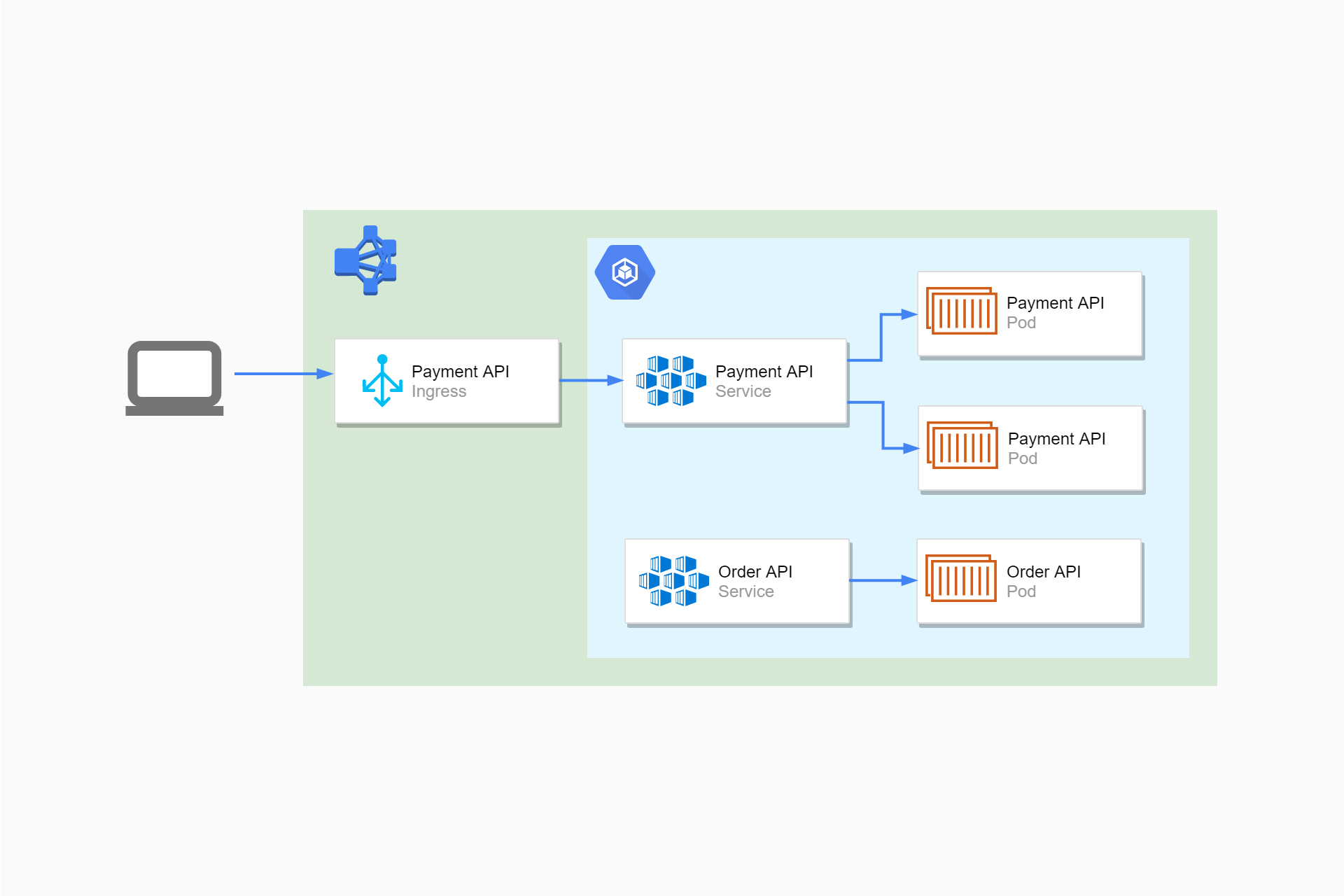
You've seen that a deployment can be used to create multiple replicas of a pod, spread across multiple nodes. This can improve performance (there's more instances of your app able to handle requests) and reliability (if one pod crashes, other pods can hopefully take up the slack).
I think of a service as effectively an in-cluster load-balancer for your pods. When you create a deployment, you will likely also create a service associated with that app's pods. If your deployment requires three instances of the "purchasing app", you'll create a single service to go with it.
When one pod needs to talk to another, for example the "Order API" needs to contact the "Payment API", it doesn't contact a pod directly. Instead, it sends the request to the service, which is responsible for passing the request to the pod.

There are a number of different networking modes to services that I won't go through here, but there's one pattern that's commonly used in Kubernetes: Services are assigned a DNS record that you can use to send requests from one pod/service to another.
For example, imagine you have a service called purchasing-api that your "Ordering API" pods need to invoke. Rather than having to hard code real IP Addresses or other sorts of hacks, Kubernetes assigns a standard DNS record to the service:
purchasing-api.my-namespace.svc.cluster.local
By sending requests to this domain, the Ordering API can call the "Purchasing API" without having to know the correct IP Address for an individual pod. Don't worry about this too much for now, just know that by creating a service it makes it easier to call your app from other pods in your cluster.
Namespaces work exactly as you would expect from the .NET world. They're used to logically group resources. In the example above, the service has been created in the
my-namespacenamespace.
tl;dr; Services are internal load balancers for a set of identical pods. They are assigned DNS records to make it easier to call them from other pods in the cluster.
Ingresses
Services are essentially internal to the Kubernetes cluster. Your apps (pods) can call one another using services, but this communication is all internal to the cluster. An ingress exposes HTTP/HTTPS routes from outside the cluster to your services. Ingresses allow your ASP.NET Core applications running in Pods to actually handle a request from an external user:

While services are internal load balancers for your pods, you can think of Ingresses as providing external load balancing, balancing requests to a given service across multiple nodes.
As well as providing external HTTP endpoints that clients can invoke, ingresses can provide other features like hostname or path-based routing, and they can terminate SSL. You'll generally configure an ingress for each of your ASP.NET Core applications that expose HTTP APIs.
Ingresses effectively act as a reverse-proxy for your app. For example, in one ingress controller implementation, Kubernetes configures your ingresses by configuring an instance of NGINX for you. In another implementation, Kubernetes configures an AWS ALB load balancer for you instead. It's important that you design your apps to be aware of the fact they're likely behind a reverse proxy, rather than being exposed directly to the internet. I'll discuss what that involves at various points throughout this series.
tl;dr; Ingresses are used to expose services at HTTP endpoints. They act as reverse proxies for your services, load-balancing requests between different services running on different nodes.
Summary
This post was a whistle-stop tour of the parts of Kubernetes I think are most important to application developers. When you deploy an ASP.NET Core application, you'll likely be configuring a deployment of pods, adding a service to expose those pods internally, and adding an ingress to expose the service publicly. In future posts in this series, I'll describe how to use theses components to deploy an ASP.NET Core application to Kubernetes.