This post is a bit of a bonus—I was originally going to include it as one of my smaller tips in the final post of the series, but it's unexpected enough that I think it's worth it having its own post.
This post deals with a problem whereby you see 502 error responses from your applications when they're being upgraded using a rolling-upgrade deployment in Kubernetes. If that's surprising, it should be—that's exactly what a rolling-update is supposed to avoid!
In this post I describe the problem, explain why it happens, and show how I worked around it by hooking into ASP.NET Core's IHostApplicationLifetime abstraction.
The setup: a typical ASP.NET Core deployment to Kubernetes
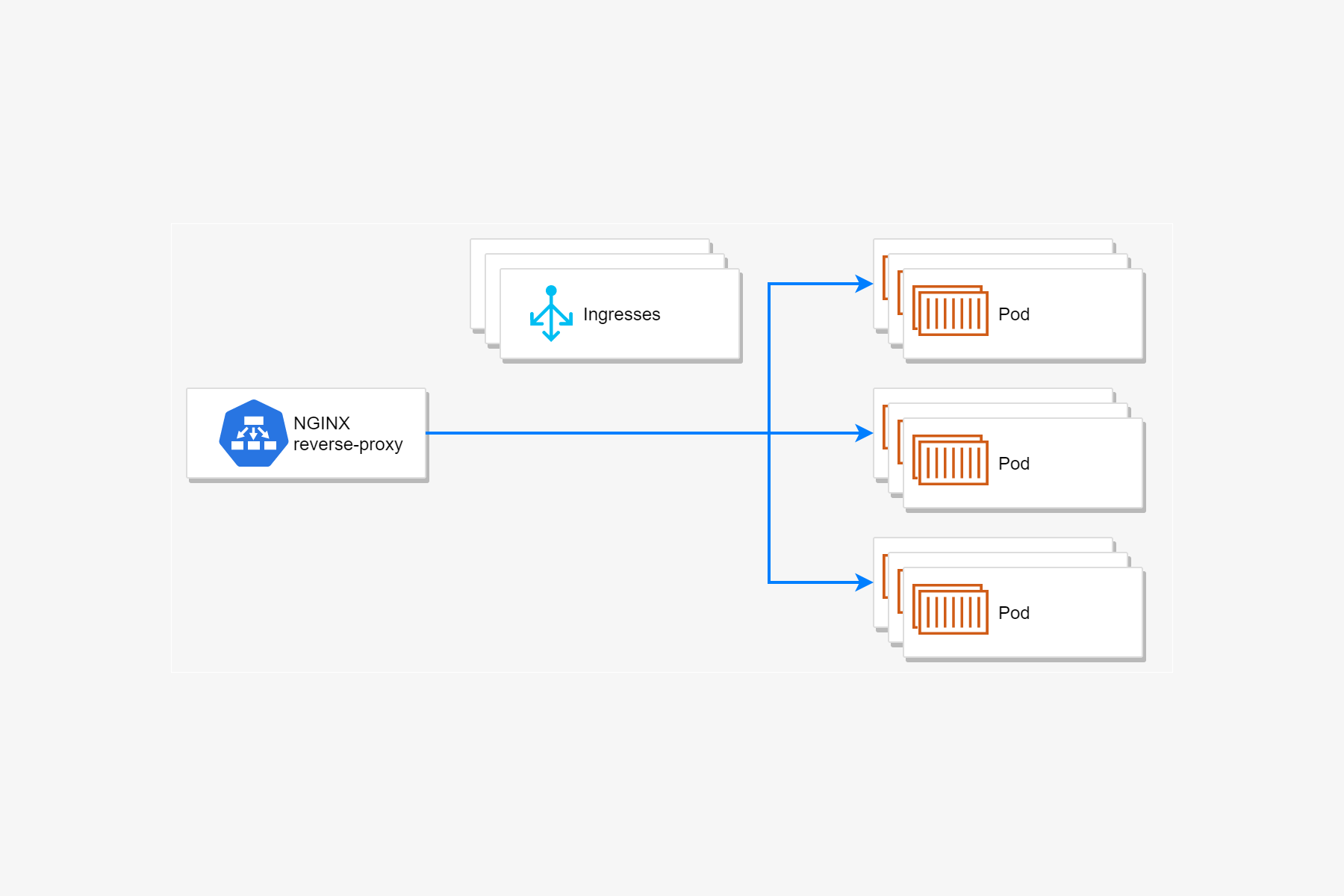
In this series I've frequently described a common pattern for deploying ASP.NET Core applications:
- Your application is deployed in a pod, potentially with sidecar or init containers.
- The pod is deployed and replicated to multiple nodes using a Kubernetes deployment.
- A Kubernetes service acts as the load balancer for the pods, so that requests are sent to one of the pods.
- An ingress exposes the service externally, so that clients outside the cluster can send requests to your application.
- The whole setup is defined in Helm Charts, deployed in a declarative way.

When you create a new version of your application, and upgrade your application using Helm, Kubernetes performs a rolling update of your pods. This ensures that there are always functioning Pods available to handle requests by slowly adding instances of the new version while keeping the old version around for a while.
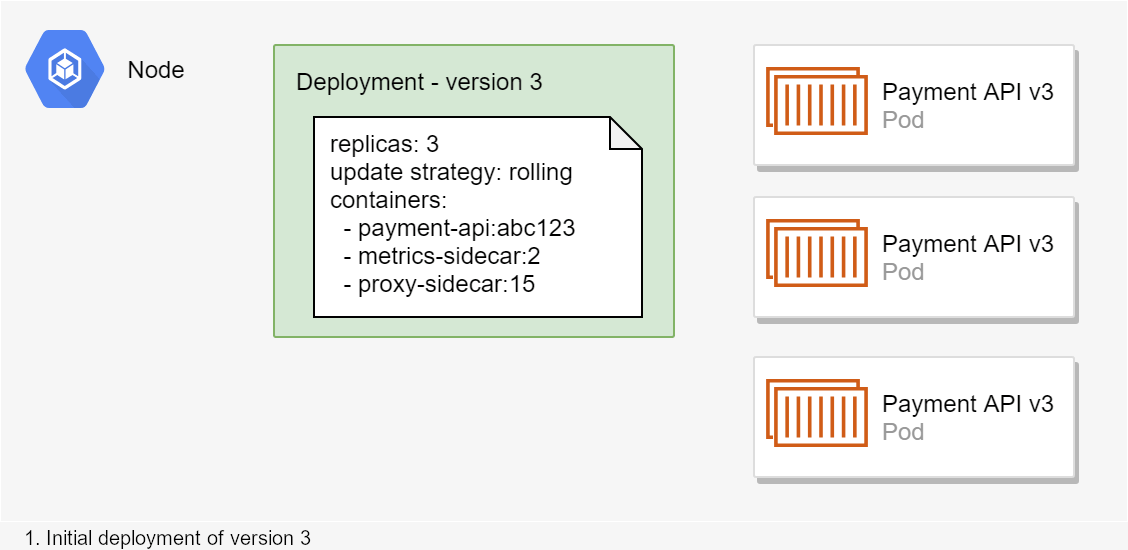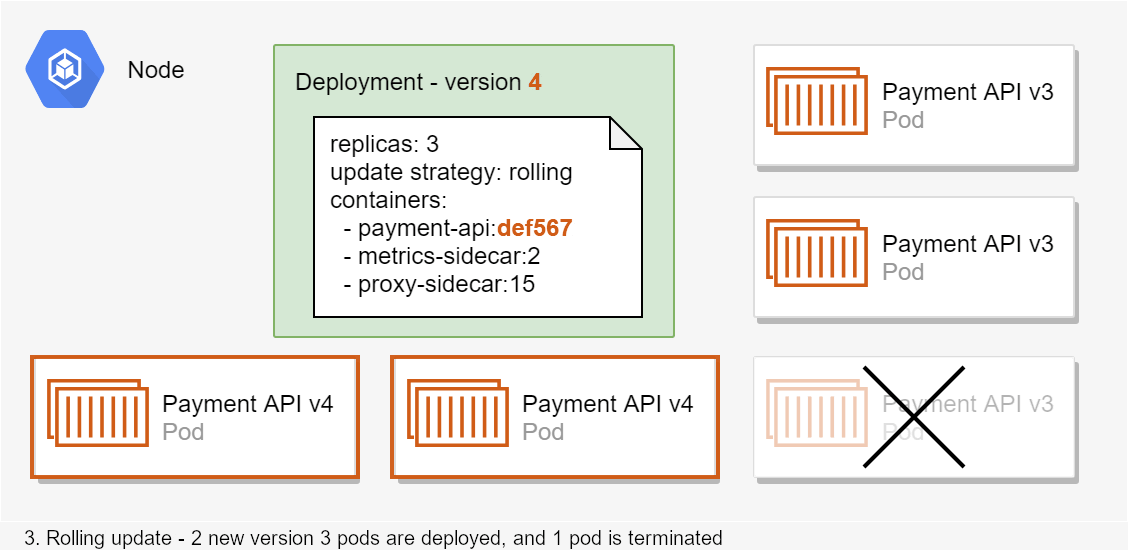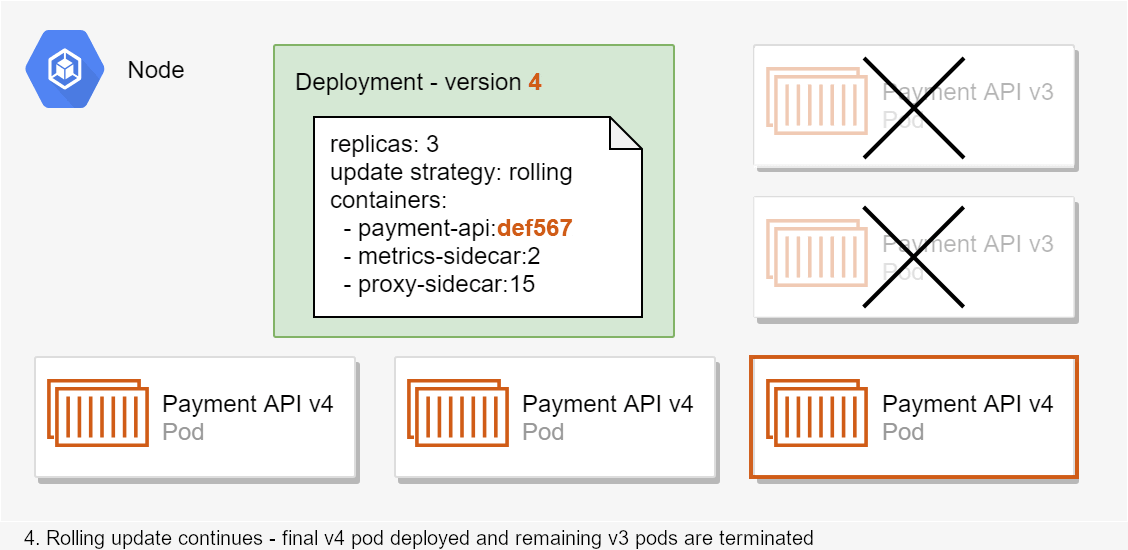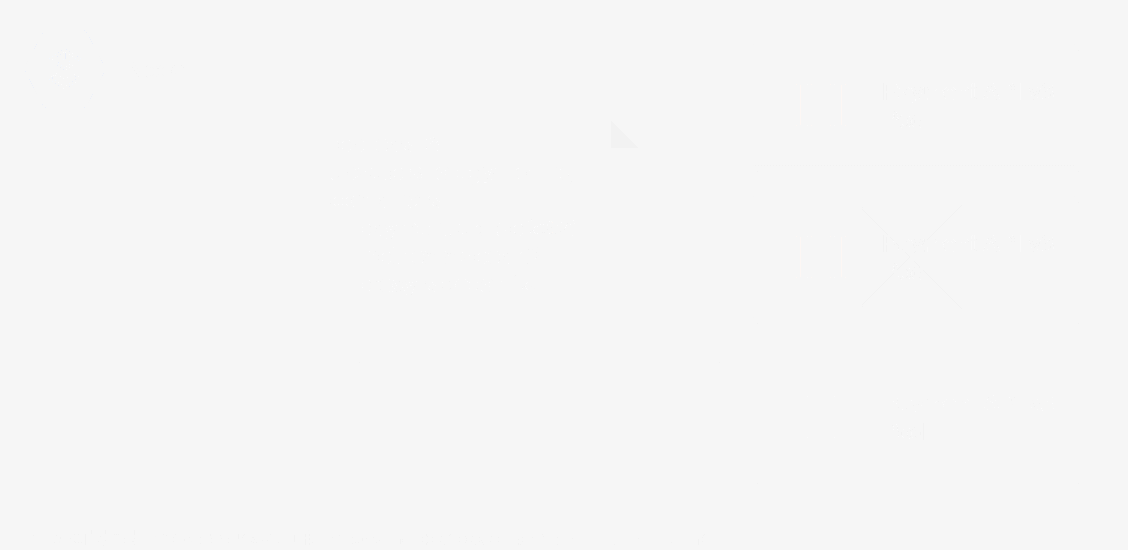
At least, that's the theory…
The problem: rolling updates cause 502s
The problem I ran into when first trying rolling-updates was that it didn't seem to work! After upgrading a chart, and confirming that there the new pods were deployed and functioning I would see failed requests for 10-20s after each deploy!
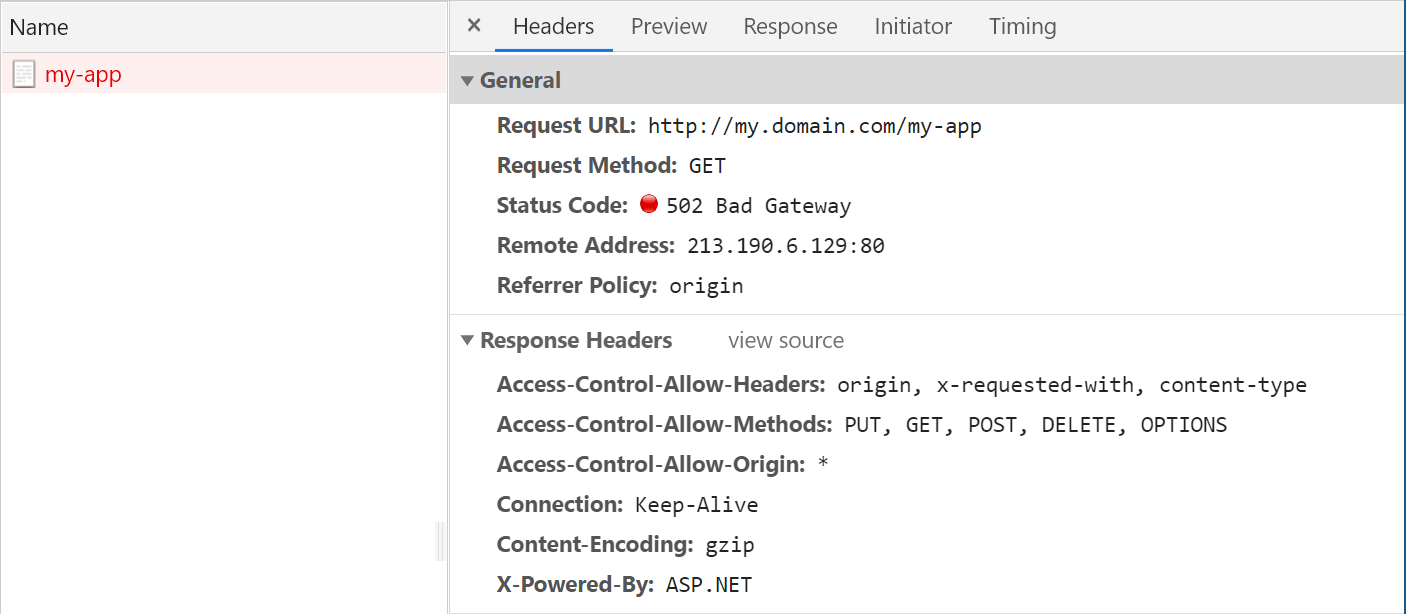
Um…ok…This really shouldn't happen. The whole point of using rolling-updates is to avoid this issue. 502 responses in Kubernetes often mean there's a problem somewhere between the Ingress and your application pods. So what's going on?
The cause: the NGINX ingress controller
The root of the problem was apparently the NGINX ingress controller we were using in our Kubernetes cluster. There's a lot of documentation about how this works, but I'll give a quick overview here.
The NGINX ingress controller, perhaps unsurprisingly, manages the ingresses for your Kubernetes cluster by configuring instances of NGINX in your cluster. The NGINX instances run as pods in your cluster, and receive all the inbound traffic to your cluster. From there they forward on the traffic to the appropriate services (and associated pods) in your cluster.

The Ingress controller is responsible for updating the configuration of those NGINX reverse-proxy instances whenever the resources in your Kubernetes cluster change.
For example, remember that you typically deploy an ingress manifest with your application. Deploying this resource allows you to expose your "internal" Kubernetes service outside the cluster, by specifying a hostname and path that should be used.
The ingress controller is responsible for monitoring all these ingress "requests" as well as all the endpoints (pods) exposed by referenced services, and assembling them into an NGINX configuration file (nginx.conf) that the NGINX pods can use to direct traffic.
So what went wrong?
Unfortunately, rebuilding all that configuration is an expensive operation. For that reason, the ingress controller only applies updates to the NGINX configuration every 30s by default. That was causing the following sequence of events during a deployment upgrade:
- New pods are deployed, old pods continue running.
- When the new pods are ready, the old pods are marked for termination.
- Pods marked for termination receive a SIGTERM notification. This causes the pods to start shutting down.
- The Kubernetes service observes the pod change, and removes them from the list of available endpoints.
- The ingress controller observes the change to the service and endpoints.
- After 30s, the ingress controller updates the NGINX pods' config with the new endpoints.
The problem lies between steps 5 and 6. Before the ingress controller updates the NGINX config, NGINX will continue to route requests to the old pods! As those pods typically will shut down very quickly when requested by Kubernetes, that means incoming requests get routed to non-existent pods, hence the 502 response.

It's worth noting that we first hit this problem over 3 years ago now, so my understanding and information may be a little out of date. In particular, this section in the documentation implies that this should no longer be a problem! If that's the case, you can discard this post entirely. I still use the solution described in here due to an "if it ain't broke, don't fix it" attitude!
Fixing the problem: delaying application termination
When we first discovered the problem, we had 3 options we could see:
- Use a different ingress controller that doesn't have this problem.
- Decrease the time before reloading the NGINX config.
- Don't shut pods down immediately on termination. Allow them to continue to handle requests for 30s until the NGINX config is updated.
Option 1 was very heavy-handed, had other implications, and wasn't an option on the table, so we can scratch that! Option 2 again, has broader (performance) implications, and wouldn't actually fix the problem, it would only mitigate it. That left option 3 as the easiest way to work around the issue.
The idea is that when Kubernetes asks for a pod to terminate, we ignore the signal for a while. We note that termination was requested, but we don't actually shut down the application for 30s, so we can continue to handle requests. After 30s, we gracefully shut down.

Note that Kubernetes (and Linux in general) uses two different "shutdown" signals:
SIGTERMandSIGKILL. There's lots of information on the differences, but the simple explanation is thatSIGTERMis where the OS asks the process to stop. WithSIGKILLit's not a question; the OS just kills the process. SoSIGTERMgives a graceful shutdown, andSIGKILLis a hard stop.
So how can we achieve that in an ASP.NET Core application? The approach I used was to hook into the IHostApplicationLifetime abstraction.
Hooking into IHostApplicationLifetime to delay shutdown
IHostApplicationLifetime (or IApplicationLifetime in pre-.NET Core 3.x) looks something like this:
namespace Microsoft.Extensions.Hosting
{
public interface IHostApplicationLifetime
{
CancellationToken ApplicationStarted { get; }
CancellationToken ApplicationStopping { get; }
CancellationToken ApplicationStopped { get; }
void StopApplication();
}
}
This abstraction is registered by default in the generic Host and can be used to both stop the application, or to be notified with the application is stopping or has shut down. I looked at the role of this abstraction in the startup and shutdown process in great detail in a previous post.
The key property for us in this case is the ApplicationStopping property. Subscribers to this property's CancellationToken can run a callback when the SIGTERM signal is received (e.g. when you press ctrl+c in a console, or Kubernetes terminates the pod).
To delay the shutdown process, we can register a callback on ApplicationStopping. You can do this, for example, in Startup.Configure(), where the IHostApplicationLifetime is available to be injected, or you could configure it anywhere else in your app that is called once on app startup, and can access DI services, such as an IHostedService.
In ASP.NET Core 3.0, I typically use "startup" tasks based on
IHostedService, as described in this post. That's the approach I'll show in this post.
The simplest implementation looks like the following:
public class ApplicationLifetimeService: IHostedService
{
readonly ILogger _logger;
readonly IHostApplicationLifetime _applicationLifetime;
public ApplicationLifetimeService(IHostApplicationLifetime applicationLifetime, ILogger<ApplicationLifetimeService> logger)
{
_applicationLifetime = applicationLifetime;
_logger = logger;
}
public Task StartAsync(CancellationToken cancellationToken)
{
// register a callback that sleeps for 30 seconds
_applicationLifetime.ApplicationStopping.Register(() =>
{
_logger.LogInformation("SIGTERM received, waiting for 30 seconds");
Thread.Sleep(30_000);
_logger.LogInformation("Termination delay complete, continuing stopping process");
});
return Task.CompletedTask;
}
// Required to satisfy interface
public Task StopAsync(CancellationToken cancellationToken) => Task.CompletedTask;
}
Register the hosted service in Startup.ConfigureServices:
public void ConfigureServices(IServiceCollection services)
{
// other config...
services.AddHostedService<ApplicationLifetimeService>();
services.Configure<HostOptions>(opts => opts.ShutdownTimeout = TimeSpan.FromSeconds(45));
}
If you run an application with this installed, and hit ctrl+c, then you should see something like the following, and the app takes 30s to shutdown:
# Normal application startup...
info: Microsoft.Hosting.Lifetime[0]
Now listening on: https://localhost:5001
info: Microsoft.Hosting.Lifetime[0]
Application started. Press Ctrl+C to shut down.
# ...
# Ctrl+C pushed to trigger application shutdown
info: MyTestApp.ApplicationLifetimeService[0]
SIGTERM received, waiting for 30 seconds
info: MyTestApp.ApplicationLifetimeService[0]
Termination delay complete, continuing stopping process
info: Microsoft.Hosting.Lifetime[0]
Application is shutting down...
# App finally shuts down after 30s
Obviously it would be very annoying for this to happen every time you shutdown your app locally, so I typically have this controlled by a setting, and override the setting locally to disable it
That's all we need in our applications, but if you try deploying this to Kubernetes as-is you might be disappointed. It almost works, but Kubernetes will start hard SIGKILLing your pods!
Preventing Kubernetes from killing your pods
When Kubernetes sends the SIGTERM signal to terminate a pod, it expects the pod to shutdown in a graceful manner. If the pod doesn't, then Kubernetes gets bored and SIGKILLs it instead. The time between SIGTERM and SIGKILL is called the terminationGracePeriodSeconds.
By default, that's 30 seconds. Given that we've just added a 30s delay after SIGTERM before our app starts shutting down, it's now pretty much guaranteed that our app is going to be hard killed. To avoid that, we need to extend the terminationGracePeriodSeconds.
You can increase this value by setting it in your deployment.yaml Helm Chart. The value should be indented to the same depth as the containers element in the template:spec, for example:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: "{{ template "name" . }}"
spec:
replicas: {{ .Values.replicaCount }}
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: {{ template "name" . }}
release: "{{ .Release.Name }}"
spec:
# Sets the value to 60s, overridable by passing in Values
terminationGracePeriodSeconds: {{ default 60 .Values.terminationGracePeriodSeconds }}
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.name }}:{{ .Values.image.tag }}"
# ... other config
In this example I set the terminationGracePeriodSeconds to 60s, to give our app time to shutdown. I also made the value overridable so you can change the terminationGracePeriodSeconds value in your values.yaml or at the command line at deploy time.
With all that complete, you should no longer see 502 errors when doing rolling updates, and your application can still shutdown gracefully. It may take a bit longer than previously, but at least there's no errors!
Summary
In this post I described a problem where the NGINX ingress controller doesn't immediately update its list of pods for a service during a rolling update. This means the reverse-proxy continues to send traffic to pods that have been stopped, resulting in 502 errors. To work around this issue, we use the IHostApplicationLifetime abstraction in ASP.NET Core to "pause" app shutdown when the SIGTERM shutdown signal is received. This ensures your app remains alive until the NGINX configuration has been updated.