
This is the last post in the series, in which I describe a few of the smaller pieces of advice, tips, and info I found when running applications on Kubernetes. Many of these are simple things to keep in mind when moving from running primarily on Windows to Linux. Others are related to running in a clustered/web farm environment. A couple of tips are specifically Kubernetes related.
It's not quite a checklist of things to think about, but hopefully you find them helpful. Feel free to add your own notes to the comments, and I may expand this post to include them. If there's any specific posts you'd like to see me write on the subject of deploying ASP.NET Core apps to Kubernetes let me know, and I'll consider adding to this series if people find it useful.
- Be careful about paths
- Treat your Docker images as immutable artefacts
- Manage your configuration with files, environment variables, and secrets
- Data-protection keys
- Forwarding Headers and PathBase
- Consider extending the shutdown timeout
- Kubernetes service location
- Helm delete --purge
Be careful about paths
This is a classic issue when moving from Windows, with its back-slash \ path separator to Linux with its forward-slash / directory separator. Even if you're currently only running on one or the other, I strongly recommend avoiding using these characters directly in any path-stings in your application. Instead use PathSeparator.
For example instead of:
var path = "some\long\path";
use something like:
var path1 = "some" + Path.PathSeparator + "long" + Path.PathSeparator + "path";
// or
var path2 = Path.Combine("some", "long", "path");
Really, be careful about paths!
Another thing to remember is casing. Windows is case insensitive, so if you have an appsettings.json file, but you try and load appSettings.json, Windows will have no problem loading the file. Try that on Linux, with its case sensitive filename, and your file won't be found.
This one has caught me several times, leaving me stumped as to why my configuration file wasn't being loaded. In each case, I had a casing mismatch between the file referenced in my code, and the real filename.
Treat your Docker images as immutable artefacts
One of the central tenants of deploying Docker images is to treat them as immutable artefacts. Build the Docker images in your CI pipeline and then don't change them as you deploy them to other environments. Also don't expect to be able to remote into production and tweak things!
I've seen some people re-building Docker images as they move between testing/staging/production environments, but that loses a lot of the benefits that you can gain by treating the images as fixed after being built. By rebuilding Docker images in each environment, you're wasting resources recreating images which are identical, and if they're not identical then you have a problem—you haven't really tested the software you're releasing to production!
If you need behavioural differences between different environments, drive that through configuration changes instead. The downside is that you can't tweak things in production, but that's also the plus side too. Your environment becomes much easier to reason about if you know noone has changed it.
Manage your configuration with files, environment variables, and secrets
The ASP.NET Core configuration system is very powerful, enabling you to easily load configuration from multiple sources and merge it into a single dictionary of key value pairs. For our applications deployed to Kubernetes, we generally load configuration values from 3 different sources:
- JSON files
- Environment Variables
- Secrets
JSON files
We use JSON files for configuration values that are static values. They're embedded in the Docker container as part of the build and should not contain sensitive values.
We use JSON files for basic configuration that is required to run the application. Ideally a new developer should be able to clone the repository and dotnet run the application (or F5 from Visual Studio) and the app should have the minimally required config to run locally.
Separately, we have a script for configuring the local infrastructural prerequisites, such as a postgres database accessible at a well know local port etc. These values are safe to embed in the config files as they're only for local development.
You can use override files for different environments such as appsettings.Development.json, as in the default ASP.NET Core templates, to override (non-sensitive) values in other environments.
As you've seen in previous posts in this series, I typically deploy several ASP.NET Core apps together, that make up a single logical application. At a minimum, there's typically an API app, a message handling app, and a CLI tool.

These applications typically have a lot of common configuration, so we use an approach I've described in a previous post, where we have a sharedsettings.json file (with environment-specific overrides) that are shared between all the applications, with app-specific appsettings.json that override them:

You can read more about how to achieve this setup here and here.
Environment variables
We use application JSON files for configuring the "base" config that an application needs to run locally, but we use environment variables, configured at deploy time, to add Kubernetes-specific values, or values that are only known at runtime. I showed how to inject environment variables into your Kubernetes pods in a previous post. This is the primary way to override your JSON file settings when running in Kubernetes.
Configuring applications using environment variables is one of the tenants of the 12 factor app, but it's easy to go overboard. The downside I've found is that it's often harder to track changes to environment variables, depending on your release pipeline, and it can make things harder to debug.
Personally I generally prefer including configuration in the JSON files if possible. The downside to storing config in JSON files is you need to create a completely new build of the application to change a config value, whereas with environment variables you can quickly redeploy with the new value. It's really a judgement call which is best, just be aware of the trade offs.
Secrets
Neither JSON files or Environment variables are for storing sensitive data. JSON files are a definite no-no: they are embedded in the Docker containers (and are generally stored in source control), so anyone that can pull your Docker images can access the values. Environment variables are less obvious—they're often suggested as a way to add secrets to your Docker containers, but this isn't always a great option either.
Many tools (such as the Kubernetes dashboard) will display environment variables to users. That can easily leak secrets to anyone just browsing the dashboard. Now, clearly, if someone is browsing your Kubernetes dashboard, then they already have privileged access, but I'd still argue that your API keys shouldn't be there for everyone to see!
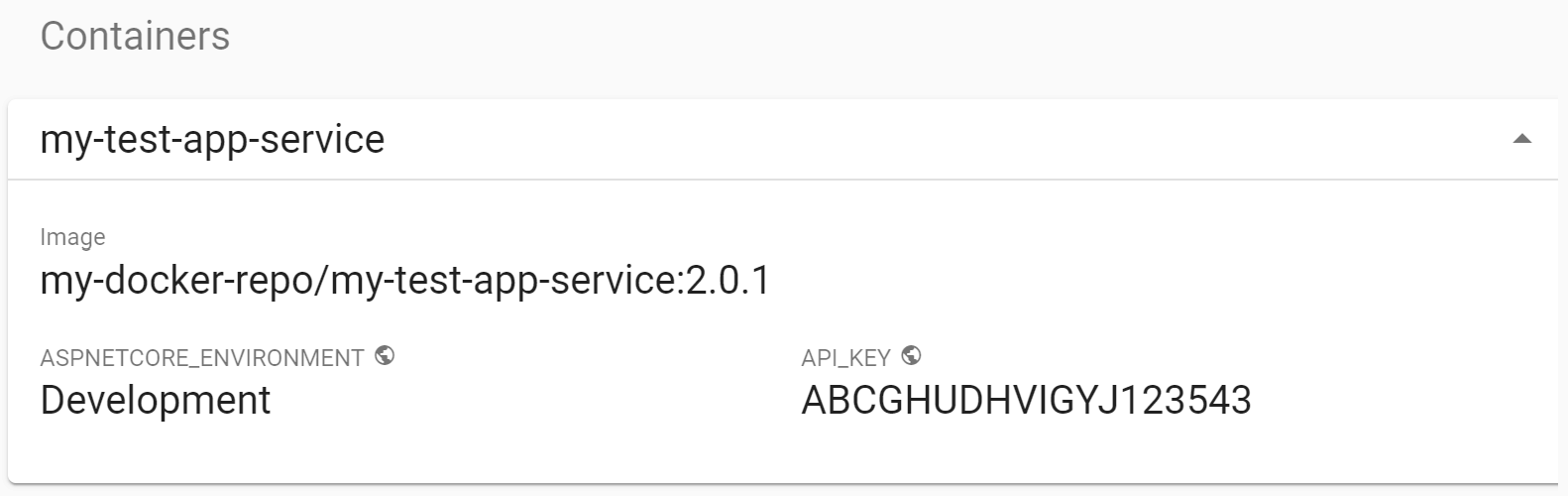
Instead, we store secrets using a separate configuration provider, such as Azure Key Vault or AWS Secrets Manager. This avoids exposing the most sensitive details to anyone who wanders by. I wrote about how to achieve this with AWS Secrets Manager in a previous post.
Kubernetes does have "native" secrets support, but this wasn't really fit for purpose last I checked. All this did was store secrets in base64, but didn't protect them. I believe there's been some headway on adding a secure backend for the Secrets management, but I haven't found a need to explore this again yet.
Data-protection keys
The data-protection system in ASP.NET Core is used to securely store data that needs to be sent to an untrusted third-party. The canonical example of this is authentication-cookies. These need to be encrypted before they're sent to the client. The data-protection system is responsible for encrypting and decrypting these cookies.
If you don't configure data-protection system correctly, you'll find that users are logged out whenever your application restart, or whenever users are routed to a different pod in your Kubernetes cluster. As a worst case, you could also expose the data-protection keys for your application, meaning anyone could impersonate users on your system. Not good!
ASP.NET Core comes with some sane defaults for the data-protection system, but you'll need to change those defaults when deploying your application to Kubernetes. In short, you'll need to configure your application to store its data-protection keys in a central location that's accessible by all the separate instances of your application.
There are various plugins for achieving this. For example, you could persist the keys to Azure Blob Storage, or to Redis. We use an S3 bucket, and encrypt the keys at rest using AWS KMS.
There are a few subtle gotchas with configuring the data-protection system in a clustered environment. I'll write a separate post(s) detailing our approach, as there are a few things to consider.
Forwarding Headers and PathBase
ASP.NET Core 2.0 brought the ability for Kestrel to act as an "Edge" server, so you could expose it directly to the internet, instead of hosting behind a reverse proxy. when running in a Kubernetes cluster, you will likely be running behind a reverse proxy.
As I mentioned in my first post, you expose your applications and APIs outside your cluster by using an ingress. This ingress defines the hostname and paths your application should be exposed at. An ingress controller takes care of mapping that declarative request to an implementation. In some implementations, those requests are translated directly to infrastructural configuration such as a load balancer (e.g. an ALB on AWS). In other implementations, the requests may be mapped to a reverse proxy running inside your cluster (e.g. an NGINX instance).
If you're running behind a reverse proxy, then you need to make sure your application is configured to use the "forwarded headers" added by the reverse proxy. For example the defacto standard headers X-Forwarded-Proto and X-Forwarded-Host headers are added by reverse proxies to indicate what the original request details were, before the reverse proxy forwarded the request to your pod.
This is another area where the exact approach you need to take depends on your specific situation. The documentation has some good advice here, so I recommend reading through and finding the configuration that applies to your situation. One of the hardest parts is testing your setup, as often your local environment won't be the same as your production environment!
One specific area to pay attention to is PathBase. If you're hosting your applications at a sub-path of your hostname e.g. the my-app portion of https://example.org/my-app/, you may need to look into the UsePathBase() extension method, or one of the other approaches in the documentation.
Consider extending the shutdown timeout
This one was actually sufficiently interesting that I moved it to a post in its own right. The issue was that during rolling deployments, our NGINX ingress controller configuration would send traffic to terminated pods. Our solution was to delay the shutdown of pods during termination, so they would remain available. I discuss both this problem and the solution in detail in the previous post.
Kubernetes service location
One of the benefits you get for "free" with Kubernetes is in-cluster service-location. Each Kubernetes Service in a cluster gets a DNS record of the format:
[service-name].[namespace].svc.[cluster-domain]
Where [service-name] is the name of the individual service, e.g. my-products-service, [namespace] is the Kubernetes namespace in which it was installed, e.g. local, and [cluster-domain] is the configured local domain for your Kubernetes cluster, typically cluster.local.
So for example, say you have a products-service service, and a search service installed in the prod namespace. The search service needs to make an HTTP request to the products-service, for example at the path /search-products. You don't need to use any third-party service location tools here, instead you can send the request directly to http://products-service.prod.svc.cluster.local/search-products. Kubernetes will resolve the DNS to the products-service, and all the communication remains in-cluster.
Helm delete --purge
This final tip is for when things go wrong installing a Helm Chart into your cluster. The chances are, you aren't going to get it right the first time you install a chart. You'll have a typo somewhere, incorrectly indented some YAML, or forgotten to add some required details. It's just the way it goes.
If things are bad enough, especially if you've messed up a selector in your Helm Charts then you might find you can't deploy a new version of your chart. In that case, you'll need to delete the release from the cluster. However, don't just run helm delete my-release, instead use:
helm delete --purge my-release
Without the --purge argument, Helm keeps the configuration for the failed chart around as a ConfigMap in the cluster. This can cause issues when you've deleted a release due to mistakes in the chart definition. Using --purge clears the ConfigMaps, and gives you a clean-slate next time you install the Helm Chart in your Cluster.
Summary
In this post I provided a few tips and tricks on deploying to Kubernetes, as well as things to think about and watch out for. Many of these are related to moving to Linux environments when coming from Windows, or moving to a clustered environment. There are also a few Kubernetes-specific tricks in there too.